

Az elmúlt néhány évben az ajánlórendszerek egyre nagyobb teret foglalnak el az életünkben, szinte bármilyen online tevékenységet végzünk jelen vannak. Ott vannak az online kereskedelemben, a hirdetésekben és az ajánlórendszerek segítenek a filmek, zenék kiválasztásában is. Ezen rendszerek célja, hogy releváns elemeket javasoljon a felhasználónak. Data Scientist-ként is előfordulnak olyan feladatok, amelyeket ajánlórendszerek segítségével tudunk megoldani. Most a két hónapos otthon tartózkodásom alatt, nem a munkám kapcsán merült fel ez a problémakör. Miután véletlenszerűen rábukkantam egy filmes adatbázisra, úgy döntöttem építek egy egyszerű ajánlórendszert magamnak, amivel újabb filmeket javasolhatok, a már megnézett filmek értékelése alapján.
Adatbázis
Ezekben a feladatokban sokszor a megfelelő adatbázis hiánya okozza a legnagyobb problémát. Előfordul, hogy adott egy jó feladat, de sajnos nem található hozzá megfelelő mennyiségű vagy minőségű adat. Ennek oka lehet, hogy az adatok nem publikusak, vagy az adatkészlet megszerzése költségesebb, mint a projekt várható haszna. Abba a problémába is sokszor beleütközünk, hogy az adatok nem megfelelő minőségűek, hiányosak vagy nem konzisztensek. Olykor saját magunknak kell létrehozni az adatbázist, ami időigényes és költséges lehet. Szerencsére én rátaláltam egy 2013 óta épülő adatbázisra.
Az általam használt adatbázis a MovieTweetings, egy olyan adatkészlet, amely twitter felhasználók filmes értékeléseit tartalmazza. Naponta gyűjti össze az információt a Twitterről, az olyan jól strukturált tweetek alapján, amelyek tartalmazzák az „I rated #IMDb” kifejezést. Ez az adatkészlet Simon Dooms által végzett kutatás eredménye, amelyet a MovieTweetings: a Movie Rating Dataset Collected From Twitter tanulmány mutat be.
Miután az adatbázis rendelkezésre állt, először is ellenőriztem a használhatóságát. Ehhez megnéztem, hogy egy-egy filmet hányan értékeltek. A legtöbbet értékelt film a Gravity, amely 3086 szavazatot kapott. Ez lényegesen elmarad az IMDb értékelések számától. Sok olyan film is volt, ami nagyon kevés szavazattal rendelkezett, ezért leszűrtem a filmeket azokra, amelyek legalább 100 értékelést kaptak, és így 1644 film maradt az adatbázisomban. Ezután leellenőriztem, hogy hogyan viszonyulnak ezeknek a filmeknek az átlagos pontszámai egymáshoz, amit a Twitteren, illetve az IMDb-n kaptak. A következő táblázatban és ábrán jól látható, hogy érdekes módon az 1644 filmből csak 10 olyan volt, ami esetén nagyobb mint 1 az eltérés az átlagos pontszámok között, holott az IMDb-n nagyságrendekkel többen értékelik a filmeket.
![]()
![]()
Így jól használhatónak fogadtam el ezt az adatbázist és ezzel dolgoztam tovább. Kiszűrtem továbbá azokat a felhasználókat, akik kevesebb, mint 20 filmre adtak értékelést. Így a felhasználók száma 6883 maradt. A kezdeti tábla (twitterdataframe) a következőket tartalmazta: felhasználó (user_id), film (movie_title), értékelés (rating).
![]()
Ajánlórendszerek
Az ajánlórendszereknek három fő típusát különböztetjük meg: Az együttműködés alapú, a tartalom alapú és a hibrid módszert, amely az előző két megoldás keveréke.
Az együttműködés alapú megközelítés kizárólag a felhasználók és az elemek közötti korábbi kölcsönhatásokon alapul, új ajánlások előállítása érdekében. Ennek a módszernek a fő gondolata az, hogy a múltbeli felhasználó-elem-interakciók elegendőek a hasonló felhasználók és hasonló elemek megtalálásához és a számolt közelségek alapján a javaslatok elkészítéséhez. Az együttműködési megközelítés fő előnye, hogy nem igényel plusz információt a felhasználókról vagy az elemekről, és ezért sok helyzetben felhasználható. Sőt minél több felhasználó értékeli az elemeket, annál pontosabbak lesznek az új ajánlások.
Ellentétben az előző a módszerrel, a tartalom alapú megközelítés esetén kiegészítő információkra is szükség van a felhasználókról és az elemekről. Ilyen információ lehet az életkor, a nem vagy bármilyen más személyes adat a felhasználóról, valamint a kategória, a rendező, az időtartam vagy egyéb jellemzők a filmekről (elemekről).
Tekintve, hogy jelen helyzetben csak annyi információ áll rendelkezésre, hogy egy-egy felhasználó milyenre értékelte a filmeket, így az együttműködés alapú módszerrel dolgoztam.
Modell
Az együttműködés alapú módszer több fajtája közül a user-user megközelítéssel foglalkoztam. Annak érdekében, hogy új ajánlást nyújtson az adott felhasználónak, megpróbálja azonosítani a leginkább hasonló ízléssel rendelkező többi felhasználót. Ezt a módszert „user központúnak” nevezik, mivel a felhasználókat ábrázolja az elemekkel való interakcióik alapján, és méri a köztük lévő távolságot. Ezután kiszámol egy „hasonlóságot” az adott felhasználó és minden más felhasználó között. Ez a hasonlósági mutató közelinek tekint két felhasználót, akiknek azonos interakciói vannak ugyanazon elemekkel. Miután kiszámította a hasonlóságokat, megtalálja a felhasználóhoz legközelebbi szomszédokat, majd a szomszédok értékelései alapján ajánlja az új elemeket.
Ebben a feladatban új filmeket szerettem volna javasolni egy adott felhasználó számára. Ehhez először, minden felhasználót ábrázoltam a különféle filmekre adott értékeléseik vektoraként. A táblából (twitterdataframe) a vektorokat a pandas.DataFrame.pivot csomaggal hoztam létre, és a hiányzó értékeket kitöltöttem nullával.
![]()
Ezek után megkerestem a szomszédokat a K legközelebbi szomszéd (K-nn) módszerével. Az algoritmus célja, hogy a film értékelések alapján megtalálja az adott felhasználóhoz legközelebb álló K számú legközelebbi szomszédot, azaz felhasználót. A szomszédok száma tetszőlegesen választható, figyelembe véve az alapbázis méretét és a feladat célját. Minél nagyobbra választjuk ezt a számot, annál távolabbi felhasználók is bekerülnek, így egyre kevésbé releváns elemeket fog javasolni a rendszer, viszont, ha nagyon kicsire állítjuk ezt a számot, akkor olyan filmeket is javasolhat, amit esetleg csak egy ember értékelt jóra. Itt a szomszédok számát 100-ra állítottam, hogy tényleg jó, de még releváns filmeket javasoljon a rendszer. A szomszédok kereséséhez az sklearn NearestNeighbors csomagját használtam. Alkalmaztam a modellt az adott felhasználóra, így megkaptam a legközelebbi 100 szomszédját.
Miután megtaláltam a legközelebbi szomszédokat, valamilyen módszerrel ki kellett választani a legnépszerűbb filmeket, majd azokat javasolni a felhasználónak, amiket még nem látott. A kiválasztás a céltól függ. Ki lehet választani azokat a filmeket, amiket a legtöbben 10-esre értékeltek, de lehet átlagos pontszám alapján is javaslatot adni. Én a következőképpen súlyoztam a pontszámokat: a rossz értékeléseket bűntettem, az átlagos értékeléseket figyelmen kívül hagytam, a jó értékeléseket pedig jutalmaztam. Ezután a kapott pontokat összegeztem minden filmre. Az így kialakult sorrendből az első 10 filmet javasoltam, amit a felhasználó még nem látott.
![]()
Ajánlás
Miután elkészült a modell, teszteltem a működését az általam értékelt filmeken. A következő táblázat azt a 20 filmet és pontszámot tartalmazza, ami alapján a legközelebbi szomszédokat kereste meg a rendszer.
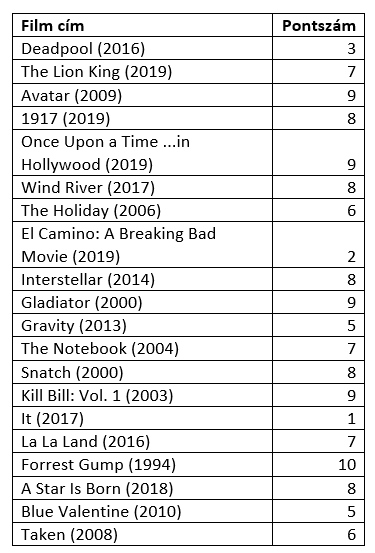
Az ajánló az alábbi filmeket javasolta nekem megnézésre:
Knives Out (2019), Avengers: Endgame (2019), Captain Phillips (2013), The Wolf of Wall Street (2013), The Shawshank Redemption (1994), Hacksaw Ridge (2016), American Hustle (2013), The Imitation Game (2014), Prisoners (2013), The Gentlemen (2019)
Mivel csak 20 filmet értékeltem előzőleg, így akadtak olyan filmek az ajánlatok között, melyeket már láttam, ennek köszönhetően tesztelni tudtam a javaslatokat. A remény rabjai (The Shawshank Redemption) és a Kódjátszma (The Imitation Game) kifejezett kedvenceim és a Phillips kapitányt is jó szívvel ajánlanám másoknak, ezért elégedett vagyok a rendszer működésével. Szerencsére azért akadt egy-két újdonság is a javaslatok között.
Felmerült problémák
A legtöbb ajánlási algoritmusban rendkívül óvatosnak kell lenni, hogy elkerüljük a népszerű termékek „gazdagabbá válását”. Más szóval, hogy rendszerünk csak népszerű elemeket javasoljon, és a felhasználók csak olyan ajánlásokat kapjanak, amelyek rendkívül közel állnak azokhoz, amelyeket már kedveltek, ezáltal nincs esélyük megismerni új elemeket. Ennek elkerülésére növelhetjük a szomszédok számát, vagy az adott felhasználó értékelési listáját bővíthetjük változatosabb filmekkel.
A másik probléma, ami felmerült miután több kollégámnak is ajánlottam filmeket, hogy az egyik kollégám az 1644 filmből 1354-et látott és értékelt. Mivel az adatbázisban a következő legtöbbet értékelt felhasználó 869 filmet látott és 500-nál több filmet csak 13 felhasználó értékelt, így a szomszéd keresésnél csak egészen távoli szomszédokat talált hozzá az algoritmus. Valamint az ajánlható filmek listája nála lecsökkent 290-re, ezért nem biztos, hogy a legrelevánsabb filmeket ajánlja neki a rendszer. Ennek a problémának a megoldására az adatbázis növelése lenne a megoldás, ami költséges és időigényes lenne, de szerencsére ez ritka eset.
Legutóbbi hozzászólások