

The importance of data-driven decision-making has never been more evident than it is today. The management, analysis, and visualization of data have advanced to a technological level that not only creates new opportunities for professionals but also enhances the efficiency of data-driven operations in businesses. The Budapest BI Forum 2024 showcased these innovations, uniting national and international experts to share their latest experiences and advancements.
This year’s schedule was dynamic, featuring topics such as artificial intelligence-enabled development tools, optimization of data modeling, and unified data platforms—subjects of great interest among attendees. The presentations were notable not just for their technical depth but also for effectively illustrating the business benefits of new solutions through practical examples. In this blog post we summarize three keynote presentations that highlighted various aspects of modern Business Intelligence, from Power BI development to VertiPaq optimization and the innovation of Microsoft Fabric.
The New PBIR Format: Development with Code and Artificial Intelligence
Introducing the PBIR Format
Mihály Kávási’s presentation highlighted the latest innovations in Power BI report development. Traditionally, Power BI files used a binary format that had significant limitations, such as a lack of version tracking, difficulties in team collaboration, and the absence of automated development tools. In contrast, the new PBIR format revolutionizes the development process by allowing Power BI files to be managed as project structures, aligning more closely with modern software development lifecycles.
Developer Tools and Integrations
The presentation showcased how PBIR integrates with popular developer tools like Tabular Editor, DAX Studio, and Azure DevOps, along with GitHub Copilot. These tools facilitate automated documentation, thorough testing, and the optimization of development processes. Notably, GitHub Copilot can generate code snippets, thereby providing valuable support to developers through artificial intelligence.
Challenges and Future Opportunities
While the new PBIR format holds great promise, Mihály cautioned that it should be used carefully due to certain limitations. For instance, instability may arise when working with larger file sizes, and creative reporting still requires a desktop or web version of Power BI.
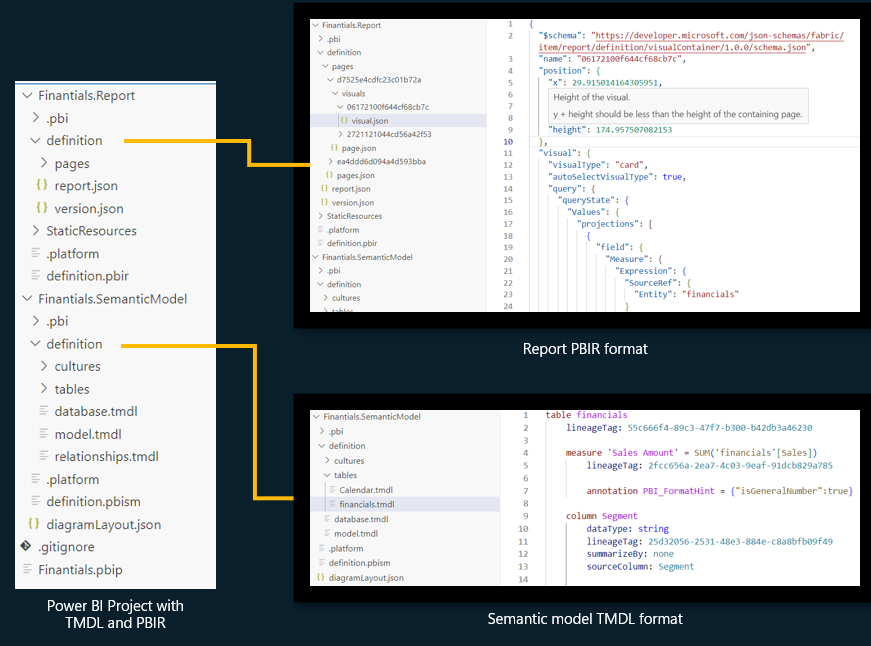
Source: Microsoft
VertiPaq: The „Brain and Muscles” of Power Bi
Understanding How VertiPaq Works
Nikola Ilic’s presentation began with an introduction to the internal engine of Power BI, known as VertiPaq. VertiPaq is a column-based, in-memory database engine that plays a crucial role in storing and processing data. It consists of two primary components: the Formula Engine, which interprets business logic, and the Storage Engine, which enables efficient data retrieval. This combination allows Power BI to manage large volumes of data quickly and reliably.
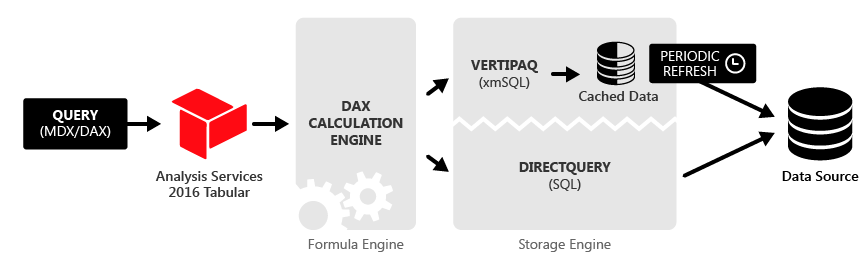
Source: SQLBI
Optimizing Data Models in Practice
The speaker delivered a detailed presentation on how effective data model design influences the performance of VertiPaq. Key points included the importance of removing unnecessary columns and rows, optimizing data types, and minimizing the use of calculated columns. The presentation emphasized that cardinality—defined as the number of unique values in a column—significantly affects both data compression and analysis speed.
Compression Algorithms: Hash Encoding and RLE
The presentation also explored the compression algorithms utilized by VertiPaq in depth. Techniques such as hash encoding and Run-Length Encoding (RLE) enable data to be stored in a compact and efficient manner. The speaker provided examples demonstrating how to select the optimal compression method depending on the data structure.
Microsoft Fabric and Copilot: Business Intelligence Powered by AI
Microsoft Fabric: Unified Data Platform
Tamás Polner’s presentation focused on Microsoft Fabric’s unified data platform, which integrates data processing, data science, and real-time analytics into a single system. One of the key benefits of Fabric is its ability to support data-driven decision-making by simplifying collaboration across different data domains.
Capabilities of the Copilot Feature
As an AI-powered tool, Copilot enhances the user experience. The presenter demonstrated how users can utilize natural language instructions to analyze data and generate new reports. Copilot can automatically create summaries, generate relevant report pages, and even add new visualizations to existing reports. This feature not only accelerates data management but also makes data analysis more accessible to business users.
OneLake: Unified Data Storage
The presentation also introduced OneLake technology, which ensures that data can be accessed from a centralized source across different platforms. This approach simplifies data storage and access processes while supporting multi-source data analysis.
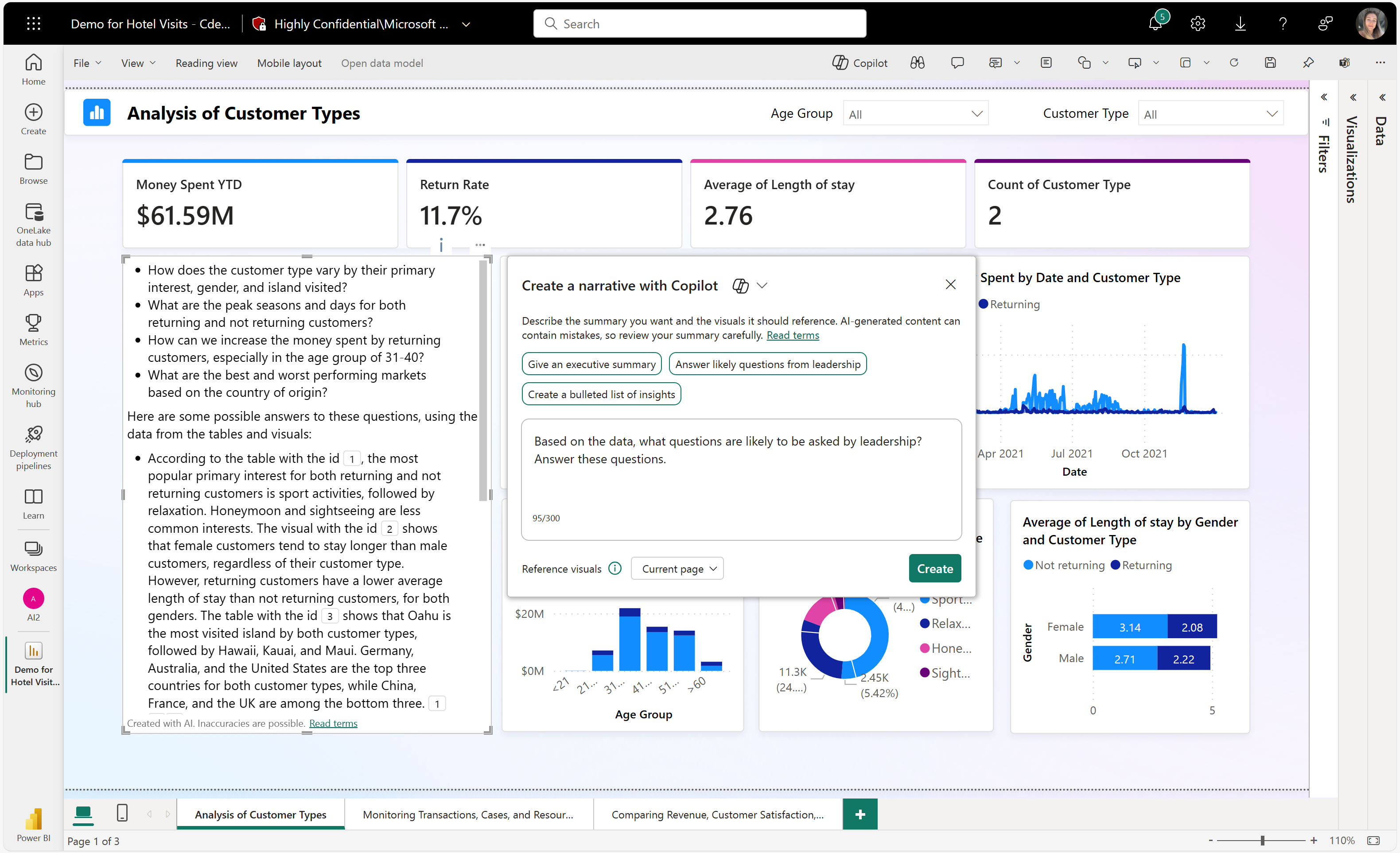
Source: Microsoft
What have we learned?
The common focus across the presentations was the rapid development of data-driven technologies and their potential to enhance business processes, making them faster and more efficient. The PBIR format and development tools boost team productivity, while VertiPaq optimization provides deeper technical insights for data modeling. Additionally, Microsoft’s Fabric and Copilot tools elevate data-driven decision-making in business. These insights allow us to implement solutions that are faster, more transparent, and more effective in our processes.
Written by Zsanett Májer and Róbert Pad





 Ahogyan a példaképeken – vagyis a dinnyeszeleteken – is látszik, az első kép az eredeti, ami az összes színréteget tartalmazza, ezt követi a piros, a zöld és a kék árnyalatok kiemelése. Jól látszik, hogy a kép dimenziói nem változtak, azonban például a piros esetén a többi réteg elemei nulla értéket kaptak, azaz teljesen feketévé váltak, így a maradék réteggel megjeleníthetővé vált a kiválasztott piros réteg. Természetesen azonos módszerrel jeleníthetők meg a kék és a zöld árnyalatok is.
Ahogyan a példaképeken – vagyis a dinnyeszeleteken – is látszik, az első kép az eredeti, ami az összes színréteget tartalmazza, ezt követi a piros, a zöld és a kék árnyalatok kiemelése. Jól látszik, hogy a kép dimenziói nem változtak, azonban például a piros esetén a többi réteg elemei nulla értéket kaptak, azaz teljesen feketévé váltak, így a maradék réteggel megjeleníthetővé vált a kiválasztott piros réteg. Természetesen azonos módszerrel jeleníthetők meg a kék és a zöld árnyalatok is.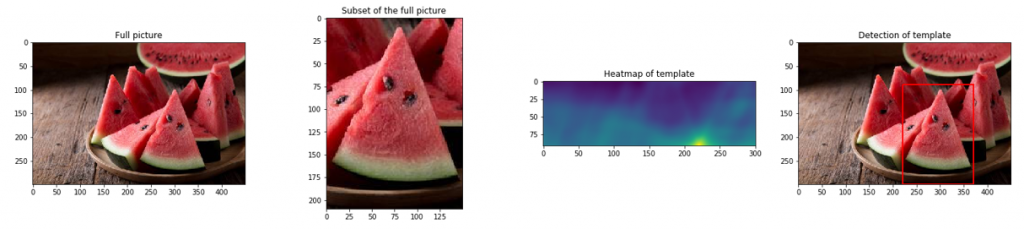 A következő képsor a folyamat lépéseit tartalmazza, aminek az első eleme a teljes kép, amiből származik a második kép, amit egyben szeretnénk is megtalálni a teljes képen. A harmadik kép egy korrelációs kép, ami egy részlet a teljes képből. Ezen jól látható, hogy kék színnel mutatja, ahol nincs pixelegyezés a nagy és a kis kép között, azonban a sárgával jelzett részen megvan a teljes egyezés. Az utolsó kép pedig a találat eredményét jeleníti meg immáron egy piros kerettel jelezve a kis kép helyzetét a teljes képen.
A következő képsor a folyamat lépéseit tartalmazza, aminek az első eleme a teljes kép, amiből származik a második kép, amit egyben szeretnénk is megtalálni a teljes képen. A harmadik kép egy korrelációs kép, ami egy részlet a teljes képből. Ezen jól látható, hogy kék színnel mutatja, ahol nincs pixelegyezés a nagy és a kis kép között, azonban a sárgával jelzett részen megvan a teljes egyezés. Az utolsó kép pedig a találat eredményét jeleníti meg immáron egy piros kerettel jelezve a kis kép helyzetét a teljes képen. A fent látható képeken megtörtént a feljebb említett szürke skálázás és a pixelek átlagolása. Az összeegyeztetés sikeresnek mondható, hiszen mind a mag, mind a héj esetében megtalálta az egyezéseket még akkor is, ha a képek teljesen más paraméterekkel rendelkeznek, és más körülmények között készítették azokat.
A fent látható képeken megtörtént a feljebb említett szürke skálázás és a pixelek átlagolása. Az összeegyeztetés sikeresnek mondható, hiszen mind a mag, mind a héj esetében megtalálta az egyezéseket még akkor is, ha a képek teljesen más paraméterekkel rendelkeznek, és más körülmények között készítették azokat.


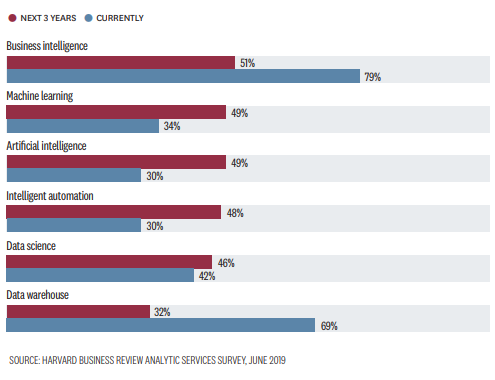

 Miután egy kisdiák lelkesedésével kijegyzeteltem a training videók anyagát és memorizáltam a törzsanyagot, igyekeztem arra fókuszálni, hogy közepesen bonyolult feladatokat anélkül is simán teljesíteni tudjak, hogy a doksit vadul böngésznem kelljen. Igazából nem tartom a manual/dokumentáció böngészését eredendően elítélendő dolognak, ennek mellőzésére praktikus okaim voltak – a vizsgán használt virtuális masina erőforrásokban nem bővelkedik (bár egy tabon a Hue plusz egy terminál ablak simán ment neki), illetve elég könnyű kifutni az időből. A vizsgán csak a hivatalos Apache doksikat lehet használni, így azért érdemes valamennyi időt ezek, illetve a sqoop manual megismerésére is szánni, ne ott lássuk ezeket először, ha mégis bajba kerülnénk. Alternatív forrásként a neten találtam még felkészítő
Miután egy kisdiák lelkesedésével kijegyzeteltem a training videók anyagát és memorizáltam a törzsanyagot, igyekeztem arra fókuszálni, hogy közepesen bonyolult feladatokat anélkül is simán teljesíteni tudjak, hogy a doksit vadul böngésznem kelljen. Igazából nem tartom a manual/dokumentáció böngészését eredendően elítélendő dolognak, ennek mellőzésére praktikus okaim voltak – a vizsgán használt virtuális masina erőforrásokban nem bővelkedik (bár egy tabon a Hue plusz egy terminál ablak simán ment neki), illetve elég könnyű kifutni az időből. A vizsgán csak a hivatalos Apache doksikat lehet használni, így azért érdemes valamennyi időt ezek, illetve a sqoop manual megismerésére is szánni, ne ott lássuk ezeket először, ha mégis bajba kerülnénk. Alternatív forrásként a neten találtam még felkészítő 


Legutóbbi hozzászólások