

Az újkori nyári olimpiák történetének talán legkülönlegesebb világjátékán vagyunk túl. Tokió rengeteg izgalmat és megannyi, eddig soha nem látott újdonságot hozott. Eleve szokatlan volt, hogy a pandémia miatt 2021-ben rendezték meg a nevében a 2020-at változatlanul hordozó versenyt, az olimpiához kapcsolódó számok sorában azonban korántsem ez a legnagyobb érdekesség. Ilyen volt az olimpia IT-s szemmel…
Cégünk, a United Consult munkatársai nem csupán a remek magyar sikerek – a hat arany-, a hét ezüst- és a hét bronzérem – miatt figyelték izgatottan a világ talán leginnovatívabb országában, Japánban zajló olimpiát, hanem mert az IT-szféra elképesztő mértékű fejlődése bizony a sportra is óriási hatással van, ez pedig Magyarország egyik vezető informatikai vállalataként természetesen minket sem hagy hidegen. Kollégáink szakmai érdeklődése ezúttal főként a bigdata-terület és a mesterséges intelligencia (AI) sportba integrált újdonságai felé irányult, melyekről például az amerikai-indiai szakportál, az Analytics Insight is beszámolt a napokban. Lássuk tehát, milyen szenzációkkal szolgált Tokió az IT világában!
A stopperórától a mesterséges intelligenciáig
„Ez volt az az olimpia, ahol a mesterséges intelligencia immár érezhetően megváltoztatta az IT sportban betöltött szerepét és jelentőségét” – hangsúlyozza Adilin Beatrice szakíró cikkében. Mint fogalmaz, a sport világában már évtizedek óta jelen van az informatika; ez, valamint a – részben a pandémia miatt – berobbanó digitalizáció pedig rendkívül erős alapot teremtett a mesterséges intelligencia térnyeréséhez. (A sport és az AI kapcsolatáról egyébként már korábbi, a Premier League 21. századi IT-vonatkozásait taglaló cikkükben is írtak nemrég.)
Persze a történet egyáltalán nem most, a tokiói olimpián kezdődött, hanem hosszú évekre, sőt évtizedekre nyúlik vissza, lényegében egyfajta IT-evolúciós folyamatként érdemes vizsgálni azt. A sportolók és edzőik régóta dolgoznak saját és konkurenseik statisztikái alapján, az egyre komplexebb adatbázisok kezelése és elemzése azonban komoly erőforrásigényekkel bír. A haladó szellemű, innovatív sportolók és menedzsereik régóta nyitottan tekintenek a mesterséges intelligencia alkalmazására mindennapi munkájuk során. A technológia ugyanis nem csupán a sporttal kapcsolatos stratégiai döntések meghozását segíti elő, hanem az egyéni teljesítmény fokozására, sőt akár egy-egy mozdulatsor finomhangolására is alkalmas.
A technológia beszivárgása nem újkeletű, lényegében már az első stopperórák megjelenésével elkezdődött – tekint vissza a cikk szerzője, majd hozzáteszi: az első lényeges áttörést 1948 jelentette, amikor elkezdték használni az Omega fantasztikus innovációját, a célfotók készítésére alkalmas fényképezőgépet. Mára a fejlődés egészen odáig jutott, hogy az AI alkalmazása teljesen elfogadott, sőt bizonyos sportágak esetében már-már általános volt Tokióban, s ez új színt, új élményeket vitt az olimpiába mind a résztvevők, mind pedig a nézők számára.
Az AI mindennapi haszna az olimpián
A mindkét területet jól ismerő sport- és IT-szakemberek szerint nem kérdés, hogy az adattudomány és a mesterséges intelligencia rövid időn belül forradalmasítja a sportipart. Lényegében ez a folyamat már el is kezdődött, szemtanúi lehettünk Japánban is. Mielőtt azonban rátérne erre, az idézett cikk szerzője néhány olyan gyakorlatias példát is említ, mely egy olyan komplex, nagy volumenű rendezvény megszervezéséhez szükséges, mint a tokiói olimpia volt. A fejlett IT-szolgáltatások (köztük az AI) segítséget nyújtottak egyebek mellett abban, hogy a világ megannyi országából érkező sportolókat szervezett körülmények között helyezhessék el, szolgálhassák ki az olimpiai faluban, hogy a résztvevők (a sportolók mellett a delegációk más tagjai, a versenybírók, a média képviselői stb.) probléma nélkül mozoghassanak a repülőtér, az olimpiai falu és a versenyek helyszínei között a világ egyik legzsúfoltabb városában.
Világszerte egyre több hír terjed az önvezető járművekről, azonban a japánoknak köszönhetően az elmúlt hetekben az eddig lényegében futurisztikusnak tűnő elképzelések a szemünk láttára váltak valósággá.
Az autonóm működő, olimpiai járművek praktikus megoldást jelentettek a mobilitási problémák kezelésére a világjátékok alatt. A részben gépi tanuláson alapuló önvezető autók ráadásul nem csupán a sportolók szállításában játszottak komoly szerepet, hanem a sporteszközöket – például gerelyeket, diszkoszokat és dobókalapácsokat is – ezek szállították az egyes helyszínek között.
A mesterséges intelligencia fontos alkalmazási területe volt a kommunikáció is, hiszen az olimpiát lebonyolítani – különösen egy olyan, nyelvileg zárt környezetben, mint Japán – hasonlóan nagy kihívás, mint megszervezni Bábel tornyának építését. A világ több mint kétszáz nemzete több mint százféleképpen beszél, az AI pedig egyszerű átjárást biztosított ezek között még a leggyakoribb idegennyelvek ismerete nélkül is. Sokan talán nem is tudják, de a tokiói olimpián mesterséges intelligenciával támogatott valós idejű fordítási rendszereket használtak, hogy a különböző országokból érkező emberek megértsék az utasításokat. A kifejezetten az ötkarikás rendezvényre fejlesztett nyelvi alkalmazás okostelefonokra vagy más kompatibilis eszközökre volt telepítve, és valós időben tolmácsolt a résztvevők között. A mesterséges intelligenciát a legkülönbözőbb nyomkövető eszközökben, a felhőalapú sugárzás támogatására, a robotasszisztensek használata során és az 5G-vel összefüggésben is használták az elmúlt hetekben Tokióban.
Mesterséges (sport)intelligencia
Ha tovább lépünk a szervezést és az infrastruktúrát érintő előnyökön, a tokiói példákat látva megállapíthatjuk azt is: a mesterséges intelligencia alkalmazása fontos áttörést jelent a sport világában. Évtizedek óta úgy tűnik ugyanis, hogy bizonyos sportágakban a versenyzők már
elérték az emberi teljesítőképesség határait, ezt jelzi az is, hogy ma már egyre ritkábban dőlnek meg olimpiai és világrekordok. A kétes eredetű, hatású és legalitású teljesítményfokozó szerek és módszerek után végre megérkezett a mesterséges intelligencia, mely az emberi mozdulatok tökéletesítése, finomhangolása révén újra lehetővé teszi, hogy a sportolók túltegyenek a nagy elődökön és csúcsokat dönthessenek. Persze ideális esetben nem csupán az eredmény számít, hanem az is, hogy a sikerek eléréséért egy-egy versenyző ne fizessen a saját egészségével. Az AI a túlhajszoltság elkerülésében, az edzésmunka optimalizálásában is segíthet, s ezzel akár a komoly sérülések vagy éppen a tragédiák is elkerülhetők.
Most lássunk néhány konkrét példát az AI használatára Tokióból!
Adilin Beatrice, az idézett cikk szerzője úgy fogalmaz, hogy a big data drasztikus szerepet játszik a sportolók teljesítményének javításában, példaként pedig a szörfözést említi. Az Egyesült Államok nemzeti szörfszövetsége rengeteg bigdata-módszert alkalmazott az elmúlt években azért, hogy segítsen sportolóinak előnyt szerezni versenytársaikkal szemben. Egyfelől saját teljesítményeiket, másfelől pedig a konkurensek eredményeit is folyamatosan elemezték, de a sportolók fiziológiai állapotának figyelemmel kísérésére is használták, beleértve a kardiovaszkuláris teljesítményt, az alvási szokásokat vagy éppen a pulzusszám változását.
Itt van egy másik innováció is. Az Intel és az Alibaba közösen készítette el a 3DAT (3D Athlete Tracking) névre keresztelt rendszerét, mely képes arra, hogy szorosan figyelemmel kísérje a sportolók mozdulatait, az adatokból pedig megfelelő, a teljesítmény fokozására alkalmas konzekvenciákat vonjon le. A 3DAT először az amerikai olimpiai próbákon debütált, Tokióiban pedig már élesben használták. Az AI-alapú rendszer öt speciális pályamenti kamerától kap vizuális adatokat, majd elküldi a felhőbe, ahol a képeket releváns, elemezhető információcsomagokká alakítják.
Végül pedig egy érdekesség, mely tökéletesen szimbolizálja az AI és a sport kapcsolatát. A Toyota mesterséges intelligenciájú humanoid kosárlabdázója a maga nemében egy igazi legenda. A robot történelmet írt 2019-ben, amikor a Guinness-világrekordot érte el „a humanoid robot által elvégzett, egymást követő legtöbb sikeres kosárlabdadobás” kategóriában. A robot Tokióban is szerepet kapott: minden reklámszünetben megmutatta dobótudását, mely az AI révén egyre csak fejlődik.
Forrás: Analytics Insight


 Ahogyan a példaképeken – vagyis a dinnyeszeleteken – is látszik, az első kép az eredeti, ami az összes színréteget tartalmazza, ezt követi a piros, a zöld és a kék árnyalatok kiemelése. Jól látszik, hogy a kép dimenziói nem változtak, azonban például a piros esetén a többi réteg elemei nulla értéket kaptak, azaz teljesen feketévé váltak, így a maradék réteggel megjeleníthetővé vált a kiválasztott piros réteg. Természetesen azonos módszerrel jeleníthetők meg a kék és a zöld árnyalatok is.
Ahogyan a példaképeken – vagyis a dinnyeszeleteken – is látszik, az első kép az eredeti, ami az összes színréteget tartalmazza, ezt követi a piros, a zöld és a kék árnyalatok kiemelése. Jól látszik, hogy a kép dimenziói nem változtak, azonban például a piros esetén a többi réteg elemei nulla értéket kaptak, azaz teljesen feketévé váltak, így a maradék réteggel megjeleníthetővé vált a kiválasztott piros réteg. Természetesen azonos módszerrel jeleníthetők meg a kék és a zöld árnyalatok is.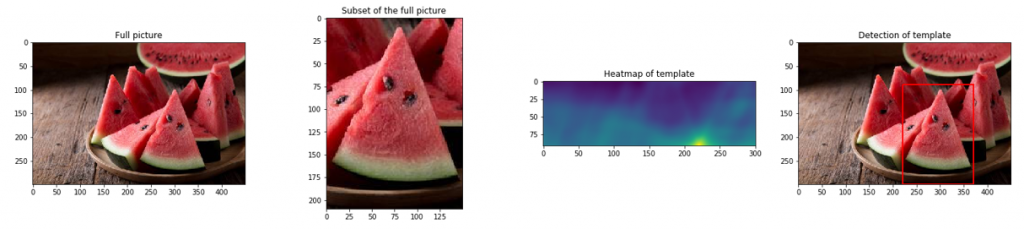 A következő képsor a folyamat lépéseit tartalmazza, aminek az első eleme a teljes kép, amiből származik a második kép, amit egyben szeretnénk is megtalálni a teljes képen. A harmadik kép egy korrelációs kép, ami egy részlet a teljes képből. Ezen jól látható, hogy kék színnel mutatja, ahol nincs pixelegyezés a nagy és a kis kép között, azonban a sárgával jelzett részen megvan a teljes egyezés. Az utolsó kép pedig a találat eredményét jeleníti meg immáron egy piros kerettel jelezve a kis kép helyzetét a teljes képen.
A következő képsor a folyamat lépéseit tartalmazza, aminek az első eleme a teljes kép, amiből származik a második kép, amit egyben szeretnénk is megtalálni a teljes képen. A harmadik kép egy korrelációs kép, ami egy részlet a teljes képből. Ezen jól látható, hogy kék színnel mutatja, ahol nincs pixelegyezés a nagy és a kis kép között, azonban a sárgával jelzett részen megvan a teljes egyezés. Az utolsó kép pedig a találat eredményét jeleníti meg immáron egy piros kerettel jelezve a kis kép helyzetét a teljes képen. A fent látható képeken megtörtént a feljebb említett szürke skálázás és a pixelek átlagolása. Az összeegyeztetés sikeresnek mondható, hiszen mind a mag, mind a héj esetében megtalálta az egyezéseket még akkor is, ha a képek teljesen más paraméterekkel rendelkeznek, és más körülmények között készítették azokat.
A fent látható képeken megtörtént a feljebb említett szürke skálázás és a pixelek átlagolása. Az összeegyeztetés sikeresnek mondható, hiszen mind a mag, mind a héj esetében megtalálta az egyezéseket még akkor is, ha a képek teljesen más paraméterekkel rendelkeznek, és más körülmények között készítették azokat.

 Forrás:
Forrás: 
 Forrás:
Forrás: 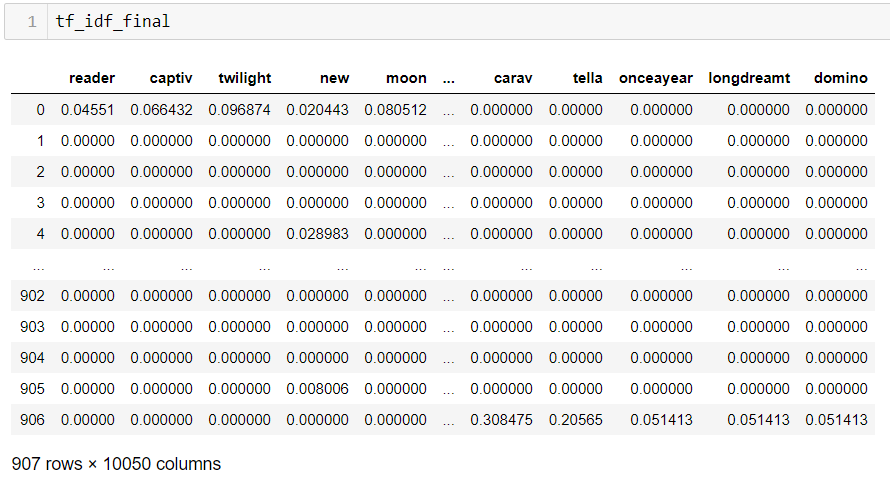


 „Az eredményekből látszik, hogy vannak bizonyos címkék – kortárs, romantikus, fantasy, ifjúsági –, amiket nagyon jól felismer a program, de azokra, amelyek ritkábban szerepeltek a tanuló halmazban – például humoros, női/férfi főszereplő, váltott szemszög, sci-fi, disztópia –, nem tanult rá olyan jól, és az új fülszövegekre nem alkalmazza ezeket a címkéket” – konstatálta Szabó-Fischer Hanna.
„Az eredményekből látszik, hogy vannak bizonyos címkék – kortárs, romantikus, fantasy, ifjúsági –, amiket nagyon jól felismer a program, de azokra, amelyek ritkábban szerepeltek a tanuló halmazban – például humoros, női/férfi főszereplő, váltott szemszög, sci-fi, disztópia –, nem tanult rá olyan jól, és az új fülszövegekre nem alkalmazza ezeket a címkéket” – konstatálta Szabó-Fischer Hanna.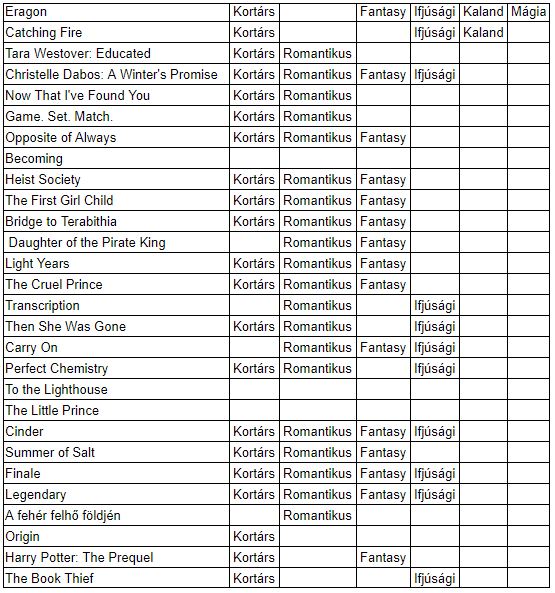 A kód
A kód
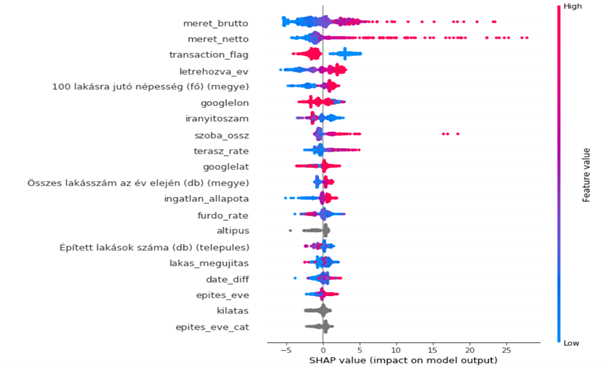 A fenti képen az ingatlan és régió tulajdonságait láthatjuk és ezek hatását az árra, ha a skála piros, akkor növeli az ingatlan árát, kékkel jelölve fordított az irány. Ezek a hatások az első pár változó esetében jól is látható, hiszen a bruttó és nettó méret növekedésével az ingatlan ára is egyre nagyobb lesz, de befolyásolja a korábban említett tranzakciós vagy kikiáltási ár is és hogy mikor lett létrehozva az ingatlan hirdetés.
A fenti képen az ingatlan és régió tulajdonságait láthatjuk és ezek hatását az árra, ha a skála piros, akkor növeli az ingatlan árát, kékkel jelölve fordított az irány. Ezek a hatások az első pár változó esetében jól is látható, hiszen a bruttó és nettó méret növekedésével az ingatlan ára is egyre nagyobb lesz, de befolyásolja a korábban említett tranzakciós vagy kikiáltási ár is és hogy mikor lett létrehozva az ingatlan hirdetés.




Legutóbbi hozzászólások