

Tudod, mi a különbség a sarki zöldséges és a képelemző algoritmus között? Az egyik kilóban, a másik pedig pixelekben méri a dinnyét. És mi a hasonlóság? Mindkettő úgy szereti, ha minél pirosabb belülről a gyümölcs. A poén persze komolytalan, a téma viszont nagyon is komoly – mutatjuk, hogyan került képbe a dinnye!
A 2010-es évek talán leglátványosabb technológiai vívmányai az önvezető autók, illetve a kép- és arcfelismerő rendszerek. Lassan egy évtizede sorra jelennek meg cikkek, tévériportok, blogbejegyzések a témában, melyekkel nem csupán az IT-szakma, de a laikus átlagember is gyakran találkozik, így viszonylag tájékozott lehet a felhasználással kapcsolatban. Azt azonban ma is kevesen tudják, hogyan is működnek ezek a rendszerek, miként „foghatja fel” egy gép, hogy mit is lát az elé táruló élő képeken vagy éppen fotókon.
E bejegyzésünkben segítünk kicsit megérteni, hogy milyen alapelvek szerint működik a képfeldolgozás, és hogy hogyan találnak meg egy-egy objektumot az algoritmusok a hatalmas pixelrengetegben. Ebben segített egy OpenCV (Open Source Computer Vision) csomag, mely bárki számára elérhető. A cikkben az alapfogalmak tisztázását követően bemutatunk két eljárást, ami segíthet a számítógép számára különböző objektumokat megtalálni, akár azonos képeken, akár teljesen más forrásból származó fotók esetében.
Kezdjük az alapoktól!
A kép képpontok, azaz a pixelek összessége, amelyek egy mátrixba csoportosulnak, és vizuálisan felismerhető, értelmezhető alakzatokat jelenítenek meg. Ezen mátrixok nagyságát befolyásolja a kép szélessége és magassága, a rétegeit pedig a színrendszer határozza meg. A fontosabb színskálák az úgynevezett rgb, hsv, hls, luv és a yiq. A továbbiakban az rgb, tehát a red, green és blue színrendszer alkalmazásával bontjuk elemeire a képeket. Az rgb rendszer esetén a kép mátrix-összetétel a következő: a mátrix magassága, a szélessége és a színrétegek száma, ami jelen rendszer mellett három. A rétegek elemei 0-tól 255-ig terjedő egész értékű számok. Fekete-fehér kép esetén a 0 a teljesen sötét, míg a 255 a fehér árnyalatot jelenti, és hasonlóan oszlik el az rgb színskálán is: a piros árnyalat esetén például a 0 a fekete, míg a nagyobb értékek a piros erősségét írja le.
Az önvezető autók működésének alapjául szolgáló, komplex képfelismerő rendszerek képesek arra, hogy azonosítsák a különböző tereptárgyakat, a járműveket, a gyalogosokat, a jelzőtáblákat és útburkolati jeleket, hogy felismerjék a jelzőlámpák fényeit. Mi azonban kezdjük az alapoktól, az alábbi dinnyés fotóval szemléltetve a rendszer működését.
 Ahogyan a példaképeken – vagyis a dinnyeszeleteken – is látszik, az első kép az eredeti, ami az összes színréteget tartalmazza, ezt követi a piros, a zöld és a kék árnyalatok kiemelése. Jól látszik, hogy a kép dimenziói nem változtak, azonban például a piros esetén a többi réteg elemei nulla értéket kaptak, azaz teljesen feketévé váltak, így a maradék réteggel megjeleníthetővé vált a kiválasztott piros réteg. Természetesen azonos módszerrel jeleníthetők meg a kék és a zöld árnyalatok is.
Ahogyan a példaképeken – vagyis a dinnyeszeleteken – is látszik, az első kép az eredeti, ami az összes színréteget tartalmazza, ezt követi a piros, a zöld és a kék árnyalatok kiemelése. Jól látszik, hogy a kép dimenziói nem változtak, azonban például a piros esetén a többi réteg elemei nulla értéket kaptak, azaz teljesen feketévé váltak, így a maradék réteggel megjeleníthetővé vált a kiválasztott piros réteg. Természetesen azonos módszerrel jeleníthetők meg a kék és a zöld árnyalatok is.
A cikkben kétféle objektum keresési eljárást fogok ismertetni, az úgynevezett template matching és a feature matching eljárásokat.
Template matching, avagy objektumillesztés
A legegyszerűbb objektumkeresési eljárások közé tartozik, hiszen a teljes kép egy kis részlete a keresett alakzat a képen, tehát a kicsi lényegében része a nagy képnek.
Ebben az esetben elegendő a kis és a nagy kép pixeleinek az összeegyeztetése, amihez többfajta műveletet is alkalmazhatunk, azonban a legismertebbek a következők:
- két különböző kép pixeleinek vagy pixel csoportjai közötti korrelációs vizsgálat (lineáris kapcsolatot leíró metrika, mely értéke -1 és 1 között található, ahol az 1 az erős azonos irányú, -1 az erős ellentétes irányú és a 0 érték pedig a kapcsolat meg nem létét írja le),
- differenciálszámítás a két kép pixel csoportjai között, ahol a hiba 0, ott lesz a teljes egyezés.
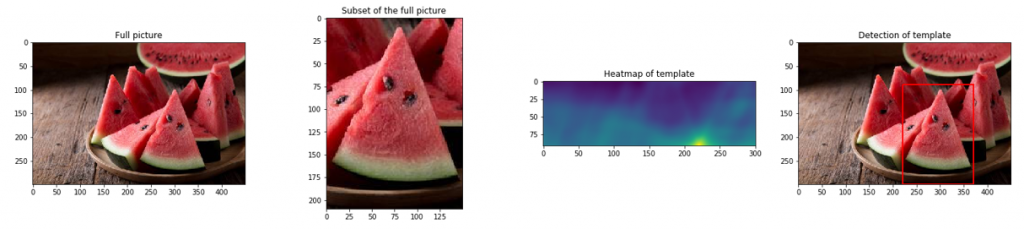 A következő képsor a folyamat lépéseit tartalmazza, aminek az első eleme a teljes kép, amiből származik a második kép, amit egyben szeretnénk is megtalálni a teljes képen. A harmadik kép egy korrelációs kép, ami egy részlet a teljes képből. Ezen jól látható, hogy kék színnel mutatja, ahol nincs pixelegyezés a nagy és a kis kép között, azonban a sárgával jelzett részen megvan a teljes egyezés. Az utolsó kép pedig a találat eredményét jeleníti meg immáron egy piros kerettel jelezve a kis kép helyzetét a teljes képen.
A következő képsor a folyamat lépéseit tartalmazza, aminek az első eleme a teljes kép, amiből származik a második kép, amit egyben szeretnénk is megtalálni a teljes képen. A harmadik kép egy korrelációs kép, ami egy részlet a teljes képből. Ezen jól látható, hogy kék színnel mutatja, ahol nincs pixelegyezés a nagy és a kis kép között, azonban a sárgával jelzett részen megvan a teljes egyezés. Az utolsó kép pedig a találat eredményét jeleníti meg immáron egy piros kerettel jelezve a kis kép helyzetét a teljes képen.
A bemutatott egyszerűbb módszertan alkalmazása több helyzetben is elegendő lehet, például akkor, amikor tudjuk, hogy a vizsgált képsokaságokon vannak pontok, melyek mindig állandók, és ezen objektumok mellett következhet be változás, így az állandó alakzatok helyzetéből meghatározható és feldolgozható az újdonság a képeken. Ezzel szemben indikátorként is alkalmazható, ha tudjuk, hogy egy képen csak egyetlen mátrixban történhet változás, és ennek a meg nem találása jelenti a változás megtörténtét.
Feature Matching, avagy sablonillesztés
A template matching esetén a hasonló pixelek feltárásánál nem volt szükség a kép előkészítésére, azonban ha a keresett kép nem része az eredetinek, hanem teljesen más forrásból származik, akkor ki kell emelni a különböző tulajdonságokat. Ezek segítségével az algoritmusok könnyebben találják meg a hasonló egységeket a képeken. Ilyen előkészítések lehetnek a következők:
- a gray scaling, avagy szürke skála, aminek a segítségével meghatározhatjuk a színárnyalatok fokozatait. Ebben az esetben a kép fekete, fehér és szürke színeket tartalmaz és csupán egy réteget, nem pedig hármat, mint az rgb színrendszer esetén,
- blurring, smoothing: zaj eltávolítása, egy előre definiált, pár képpont nagyságú mátrix mentén a teljes képen hajt végre képpontátlagolást → ennek következtében a megkapjuk azokat a képrészleteket, ahol a legnagyobb fényváltozások fellelhetők a képen. Fontos figyelni, hogy ennek következtében a kép veszít élességéből így ezt figyelembe tartva kell meghatározni ezeknek a beavatkozásoknak a súlyát.
A feature matching különböző algoritmusok összessége, amelyek együttes alkalmazásával képes megtalálni két különböző, azonban hasonló kép közötti hasonló egységeket. Ezekben a következő algoritmusok segítenek (a lista nem teljes):
- edge detection, avagy az élek feltárása: alapvető fontossága van, hiszen a képek nagy részletességgel bírhatnak, így ennek a csökkentésére szolgál az algoritmus, aminek segítségével egyszerűbbé válik a képfeldolgozás a számunkra is fontos élek feltárásával.
- contour detection, avagy a kontúrvonalak megtalálása: segít meghatározni egyes tárgyak formáját, kiterjedését, segítve az elválasztást a többi tárgytól.
A feature matching alkalmazása két pontból tevődik össze. Először is a korábbiakban felsorolt eszközök segítségével feltárja mindkét kép esetében a kulcsfontosságú részeket a képeken. Ezek lehetnek a különböző élek, kontúrok. Ezt követően a két kép esetén meghatározott kulcsfontosságú elemeket hasonlítja össze és rögzíti az összes egyezést. Mivel mindkét kép esetén több kulcsfontosságú elemet is vizsgál, így több esetben is előfordulhat, hogy lehetnek rosszabb és jobb egyezések is a két kép esetén. Tanácsos a folyamatot követően csak a legjobb egyezéseket kiválasztani.
 A fent látható képeken megtörtént a feljebb említett szürke skálázás és a pixelek átlagolása. Az összeegyeztetés sikeresnek mondható, hiszen mind a mag, mind a héj esetében megtalálta az egyezéseket még akkor is, ha a képek teljesen más paraméterekkel rendelkeznek, és más körülmények között készítették azokat.
A fent látható képeken megtörtént a feljebb említett szürke skálázás és a pixelek átlagolása. Az összeegyeztetés sikeresnek mondható, hiszen mind a mag, mind a héj esetében megtalálta az egyezéseket még akkor is, ha a képek teljesen más paraméterekkel rendelkeznek, és más körülmények között készítették azokat.
Az önvezető autók persze sokkal bonyolultabb és szofisztikáltabb rendszereket használnak, azonban az alapjai ezekből a folyamatokból tevődnek össze. Ezen alkalmazások segítségével képes meghatározni a sávokat, klasszifikációval a felismert táblákat és más alapvető funkciók összességét, ami a biztonságos vezetéshez szükséges. Talán egyszer majd az útszéli dinnyeárusnál is megáll, ha egy mézédes görögre vágyik a sofőr – azt ugyanis már tudjuk, hogy a dinnye felismerésére is képes a technológia.

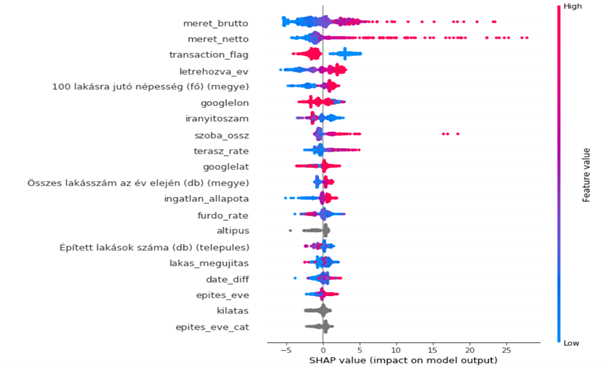 A fenti képen az ingatlan és régió tulajdonságait láthatjuk és ezek hatását az árra, ha a skála piros, akkor növeli az ingatlan árát, kékkel jelölve fordított az irány. Ezek a hatások az első pár változó esetében jól is látható, hiszen a bruttó és nettó méret növekedésével az ingatlan ára is egyre nagyobb lesz, de befolyásolja a korábban említett tranzakciós vagy kikiáltási ár is és hogy mikor lett létrehozva az ingatlan hirdetés.
A fenti képen az ingatlan és régió tulajdonságait láthatjuk és ezek hatását az árra, ha a skála piros, akkor növeli az ingatlan árát, kékkel jelölve fordított az irány. Ezek a hatások az első pár változó esetében jól is látható, hiszen a bruttó és nettó méret növekedésével az ingatlan ára is egyre nagyobb lesz, de befolyásolja a korábban említett tranzakciós vagy kikiáltási ár is és hogy mikor lett létrehozva az ingatlan hirdetés.
Legutóbbi hozzászólások