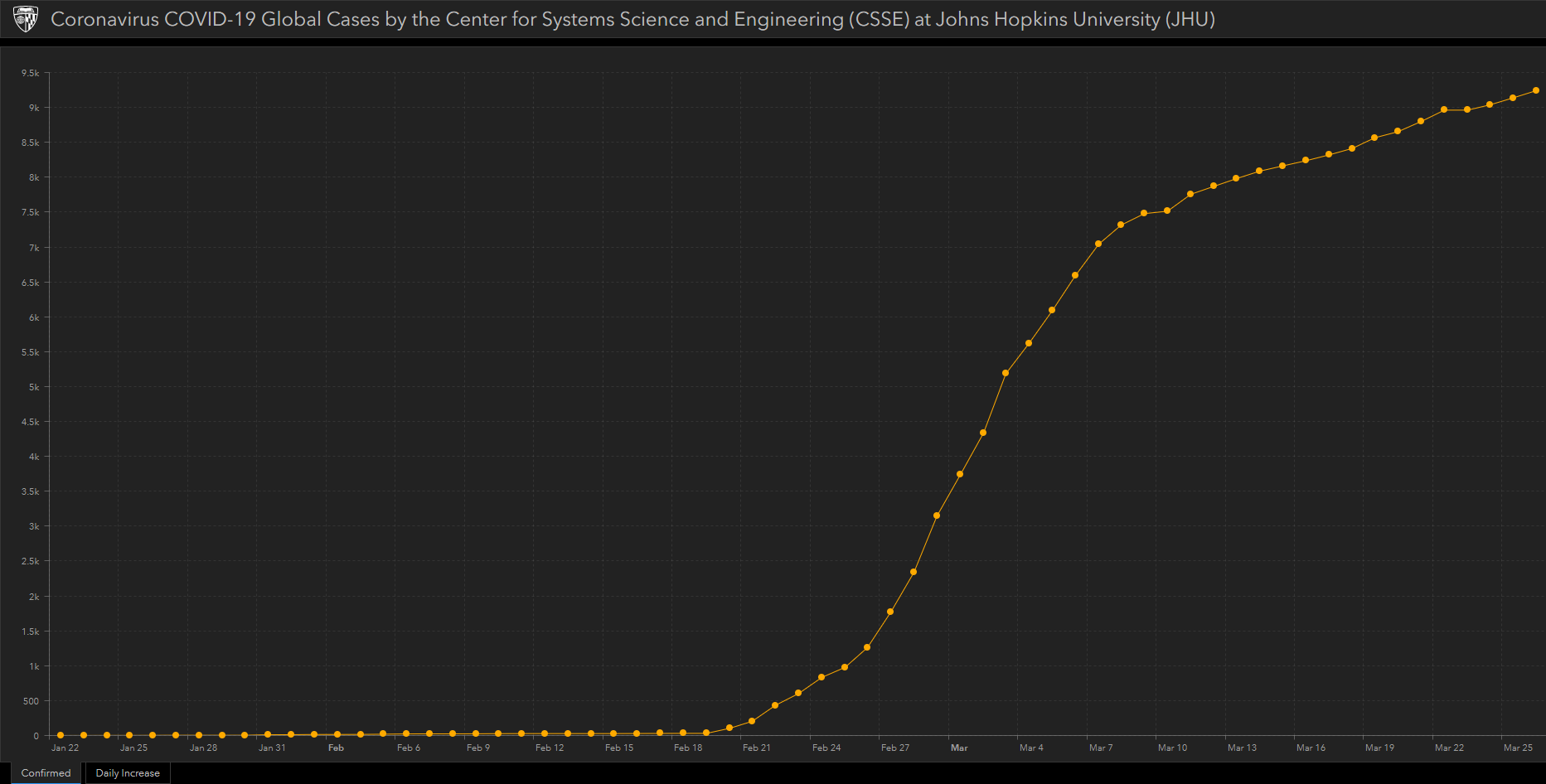
Az elmúlt hetekben alapjaiban forgatta fel társadalmunkat és világról – különösen annak biztonságáról – alkotott képünket a Kínából indult koronavírus-járvány, és persze a globális felmelegedés témája is folyamatosan foglalkoztatja a közvéleményt.
A 21. században egyre nagyobb jelentőséggel bírnak és egyre pontosabbak a különböző prognózisok. Vajon az ezek mögött álló előrejelző algoritmusok tényleg alkalmasak arra, hogy megbízható információkkal szolgáljanak például az időjárásról, a közúti forgalom, esetleg a részvényárfolyamok alakulásáról, vagy akár a járványok terjedéséről? Erre is választ keresünk a Facebook Prophet gyakorlati bemutatásán keresztül.
Nem kérdés, hogy mindennapi életünket egyre jobban befolyásolják a különböző előrejelző algoritmusok. Elég, ha csak az időjárás-előrejelzésre, a forgalmi prognózisokra vagy a részvényárfolyamok előrejelzésére gondolunk. „Vajon milyen idő lesz holnap? Ha holnap arra indulok kocsival, vajon dugóba kerülök? Vajon most érdemes beszállni ebbe az üzletbe?” – annyira gyakorlatias kérdések ezek, hogy akár az elmúlt fél órában is hallhattuk volna valakitől, vagy akár mi magunk is feltehettük volna bármelyiket.
Még ha nem is tudatosul bennünk, számos előrejelzést „futtatunk” magunk is: korán indulunk, hogy legyen hely a munkahelyi parkolóban, hogy ne kelljen sorba állni a menzán; esetleg megpróbáljuk egy korai vagy éppen késői hazaindulással a dugót elkerülni; és így tovább. Mindez tapasztalataink alapján az esetek többségében működik is, ha pedig tévedünk, olyan nagy kockázattal jellemzően nem jár.
Amikor az adatok jóslásának következménye van
Az üzleti életben az előrejelzések ennél sokkal racionálisabban működnek, és persze nagyobb téttel is bírnak. A forgalmi adatok előrejelzése például egy rendszerüzemeltetéssel foglalkozó vállalatnál kulcsfontosságú. Még ha tudnák is úgy méretezi a rendszereiket, hogy azok az elképzelhető legnagyobb forgalmat is elbírják, nem lenne költséghatékony azt mindig a maximális kapacitáson üzemeltetni. Ehelyett inkább a korábbi minták alapján próbálják megbecsülni a várható forgalmat, és az IT-infrastruktúrát az előrejelzéshez méretezni. Szerencsére az elasztikus skálázhatóság ma már nem probléma.
Egy call centernél sem mindegy, hogy mikor hány operátor dolgozik. Az sem volt mindegy, hogy a 2000-es évek derekán a telekommunikációs vállalatok mekkorának becsülték az év végi SMS-forgalmat, hiszen köztudott volt, hogy akkortájt az rövid szöveges üzenetek nagy része karácsonyra és szilveszterre koncentrálódott.
Az előrejelzés-automatizálás előretörése minden területen törvényszerű, így ma már az interneten is számos algoritmus elérhető. Egyikre sem tekinthetünk természetesen mindent tudó varázsgömbként, de van egy-két említésre méltó közöttük. Ebben a bejegyzésben a Facebook által publikált generikus prediktív elemzési megoldást vizsgáljuk: kipróbáltuk a Mark Zuckerberg és fejlesztői csapata „prófétáját”.
A Facebook Prophet egy Python és R nyelven használható előrejelző eszköz, melyet Facebook data science csapata fejlesztette ki a Stan fejlesztőeszköz használatával. Szükséges bemenete egy timestamp típusú attribútum és egy hozzá tartozó numerikus érték. Ebből adódóan ez az eszköz azokra az esetekre hasznos, mikor az adatnak szezonális tartalma van. Tapasztalataink alapján leginkább napi bontású, legalább egy évet tartalmazó adatok elemzésére alkalmas. Az implementációja követi az sklearn fit és predict függvények struktúráját.
A Prophet paraméterezhetősége
A Prophet erőssége a paraméterezhetőség, a lehetőség olyan információk átadására a modellnek, amelyek alapvetően az adatból nem következnek, de szeretnénk azokat figyelembe venni egy megbízhatóbb előrejelzés létrehozásakor.
- Saturating Forecasts: minimum(floor), maximum(cap) érték meghatározása a perdiktálás keretek között tartása érdekében. Valamely konstans keretérték megadása, ami az adott előrejelzés logikája alapján szükséges lehet.
- Trend Changepoints: az emberi ismeretekkel előre sejthető, jövőbeli trendben számíthatóan bekövetkező váltópontok számának meghatározása (n_changepoints), trend flexibilitásának beállítása (changepoint_prior_scale) vagy a váltópontok helyének meghatározása (changepoints). Ilyen lehet például a labdarúgó-világbajnokság fináléja.
- Seasonality and Holiday Effects: szezonalitás meghatározása (add_seasonality), alapvetően heti és éves intervallumokkal számol a modell. Ünnepek meghatározása (holidays). Abban az esetben, ha szeretnénk meghatározni ilyen ünnepi dátumokat, akkor azt a múltra és jövőre vonatkozóan is meg kell tenni, különben nem veszi figyelembe a modell. A különböző ünnepek között meghatározható prioritás (prior_scale) és az ünnepi hatások csillapítása is lehetséges (holidays_prior_scale).
- Outliers: Az outlier adatok kezelésére azt javasolják, hogy egyszerűen csak cseréljük le nem létező adatra, mert a Prophet jól kezeli a hiányzó adatokat.
- Non-Daily Data: Abban az esetben, ha nem éves adatokra tanítjuk be a modellünket, akkor az előre jelzésre is olyan intervallumot használjunk, mint amit a tanító halmazban.
Időjárás-előrejelzés
A Prophet eszköztárának kipróbálására Budapest egy kerületének a hőmérsékleti adatait használtuk fel, mint erősen szezonális adatokat. Az adathalmazunk 1901. 01. 01-tól 2010. 12. 31-ig tartalmaz hőmérséklet adatokat napi bontásban. Az utolsó 2010-es évet vettük ki a tanító halmazból és használtuk fel az előrejelzés visszamérésére.
# Eredeti adathalmaz oszlopainak átnevezése
df = df.rename(columns={'#datum': 'ds', 'd_ta': 'y'})
data = df[['ds', 'y']]
# Dátum formátum megváltoztatása
training = data[data['ds']<'2010-01-01'] test = data[data['ds']>='2010-01-01']
# Modell létrehozásda és tanítása
m = Prophet(changepoint_prior_scale=0.5)
m.fit(training)
# Jövőbeli dátum intervallum létrehozása
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
# Vizualizáció
plt.plot( forecast_2010['ds'], forecast_2010['yhat']
         ,forecast_2010['ds'], forecast_2010['yhat_lower']
         ,forecast_2010['ds'],forecast_2010['yhat_upper']
         ,forecast_2010['ds'],test_2010['y'] )
plt.show()
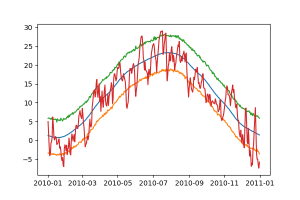 A fenti ábrán a 2010-es év valós időjárása piros vonallal látható. A Prophet által illesztett előrejelzés a kék vonal és a hozzá tartozó narancs és zöld színnel ábrázolt y_lower és y_upper, felső és alsó határérték.
A fenti ábrán a 2010-es év valós időjárása piros vonallal látható. A Prophet által illesztett előrejelzés a kék vonal és a hozzá tartozó narancs és zöld színnel ábrázolt y_lower és y_upper, felső és alsó határérték.
Decemberre illesztett görbe:
forecast_december = forecast.tail(31)
test_december = test.tail(31)
plt.plot( forecast_december['ds'], forecast_december['yhat']
         ,forecast_december['ds'], forecast_december['yhat_lower']
         ,forecast_december['ds'],forecast_december['yhat_upper']
         ,forecast_december['ds'],test_december['y'] )
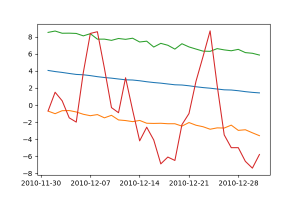
Az decemberre vonatkozó előrejelzés megmutatta, hogy kisebb intervallumok kiemelése esetén sokkal nagyobb arányban esik a prediktált felső és alsó határértékeken is kívül a valós hőmérséklet. Mint láttuk, az éves előrejelzésnél lévő körülbelüli +/– 5 fokos felső és alsó határon belülre kerülnek az akkori valós hőmérsékleti adatok túlnyomó többsége.
Októberre illesztett görbe:
forecast_oct= forecast[forecast['ds']>='2010-10-01']
forecast_oct = forecast_oct[forecast_oct['ds']='2010-10-01']
test_oct = test_oct[test_oct['ds']<'2010-11-01']
plt.plot( forecast_oct['ds'], forecast_oct['yhat']
         ,forecast_oct['ds'], forecast_oct['yhat_lower']
         ,forecast_oct['ds'],forecast_oct['yhat_upper']
         ,forecast_oct['ds'],test_oct['y'] )
plt.show()
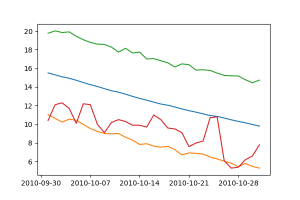
Az októberi adatok vizsgálatakor látható, hogy egy hőmérsékletben kevésbé ingadozó hónap esetén meglehetőségen pontos előrejelzést kapunk a modelltől. Ebben az esetben például a prediktált és alsó határérték közé esik – kevés kivétellel – az összes valós hőmérsékleti érték.
Prophet a globális felmelegedésről
Érdekességképpen kipróbáltuk, milyen következtetést von le a jövő időjárásra vonatkozóan a Prophet. Megnéztük, milyen előrejelzést ad száz év hőmérsékletadatait figyelembe véve a 2039-es évre vonatkozóan.
future_forecast = forecast[forecast['ds']>='2039-01-01']
future_forecast.head()
future_forecast.tail()
test_2010_cut = test_2010[test_2010['ds']<='2010-12-24']
future_forecast.tail()
test_2010_cut.tail()
plt.plot( future_forecast['ds'], future_forecast['yhat']
         ,future_forecast['ds'],test_2010_cut['y'] )
plt.show()
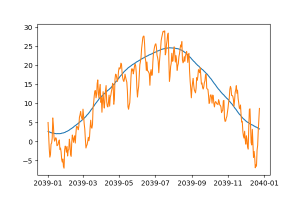
Ebben az esetben a teljes adathalmazt felhasználtuk a tanításra 1901.01.01-től 2010.12.31-ig és a következő 30 évre illesztettünk egy görbét a Facebook Prophet segítségével. A kékkel látható a 2039-es évre prediktált görbe és sárgával az adathalmazunk utolsó 2010-es évének hőmérséklete. Alapozva az elmúlt 100 év hőmérsékleti trendjére, szinte az év minden napján jó pár fokkal magasabb hőmérséklet várható.
A Facebook Prophet alapvetően egy újabb nem-lineáris regresszióval dolgozó előrejelző eszköz, ami specifikus esetekben, leginkább a benne implementált paraméterezhetőségével tud hasznos segítséget adni.
via facebook.github.io/prophet/
Tekintsd meg a legfrissebb adatokkal kapcsolatos előrejelzéseinket:
https://datandroll.hu/2020/02/12/adatelemzes-trend-bizni-az-adatokban/
https://datandroll.hu/2020/01/29/2020-az-adatok-eve-lesz/
Nézz körbe a Big Data szolgáltatásaink között:
https://thebigdataplatform.hu/big-data-uzleti-megoldasok/
Ha érdekel a cégünk, csapatunk, esetleg csatlakoznál, látogass el a főoldalunkra:
https://united-consult.hu/





Legutóbbi hozzászólások