

When developing data and business intelligence (BI) solutions, the success of a project depends not only on technology but also significantly on the composition and operation of the team. There are situations where body shopping—such as for short, clearly defined tasks or specific expert needs—can be an effective solution.
However, if the project is longer-term, more complex, or carries substantial business risk and requires broad expertise, a managed, heterogeneous Scrum team is often a more advantageous choice.
Stable, Multi-Domain Expertise Experts in a managed Scrum team typically begin with a shared understanding of the methodology, and as the project progresses, they gradually become a truly cohesive unit. Throughout every phase of the project—data architecture design, data cleansing, analysis, visualization, etc.—the necessary competencies are available and continuously evolving. In contrast, with body shopping, the client generally needs to assemble multiple independent specialists, which entails more coordination and greater risk.
Continuous and Coordinated Feedback Both a managed team and a body shopping model can operate on a sprint-based approach. The main difference is that in a managed Scrum team, regular retrospectives and collective accountability are inherent to the process. This means that everyone involved—from developers to testers and BI analysts—works together closely to respond to new requirements or emerging challenges. As a result, development directions and risks become more visible, facilitating more effective decision-making.

Reduced Management Overhead The Scrum Master oversees processes and team collaboration, while the Product Owner focuses on the project’s business priorities and the long-term utilization of the BI solution. This allows the client to avoid day-to-day coordination tasks and instead concentrate on strategic matters. In a body shopping scenario, the client is responsible for coordinating individuals, which can work well if the necessary internal resources and leadership expertise are in place. However, it can become overwhelming in more complex projects.
Stability and Knowledge Sharing A managed Scrum team generally plans for a longer time horizon, so the knowledge gained stays within the project and is not lost when experts move on. This is particularly important in the BI field because a deep understanding of how systems and data interrelate significantly influences the project’s success. With a body shopping model, there is a higher likelihood of turnover, and if a key expert leaves, transferring knowledge can pose a serious challenge.
Better Risk Management and More Effective Decision-Making Mechanisms such as retrospectives, shared backlog management, and transparent communication—built into managed Scrum teams—help quickly identify and resolve risks. Because the team jointly bears responsibility for the success of the development, there is less time spent coordinating separate parties. Although it is possible to implement similar processes in a body shopping environment, it often falls to the client to initiate and maintain these practices.
Summary
Although body shopping can be a viable solution in certain situations—for well-defined tasks or short-term projects—a managed, heterogeneous Scrum team can prove to be a more advantageous choice in many cases. This is especially true if the project’s length, complexity, or the company’s BI requirements demand deep expertise and continuous collaboration. It’s important to weigh the project’s complexity, available in-house resources, and long-term development objectives. If your aim is a stable, efficient, and long-term partnership, a managed Scrum team is more likely to deliver the desired results.


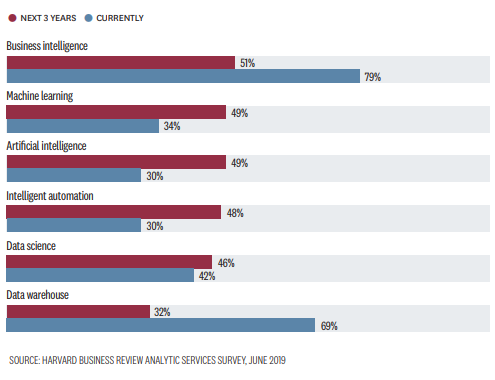
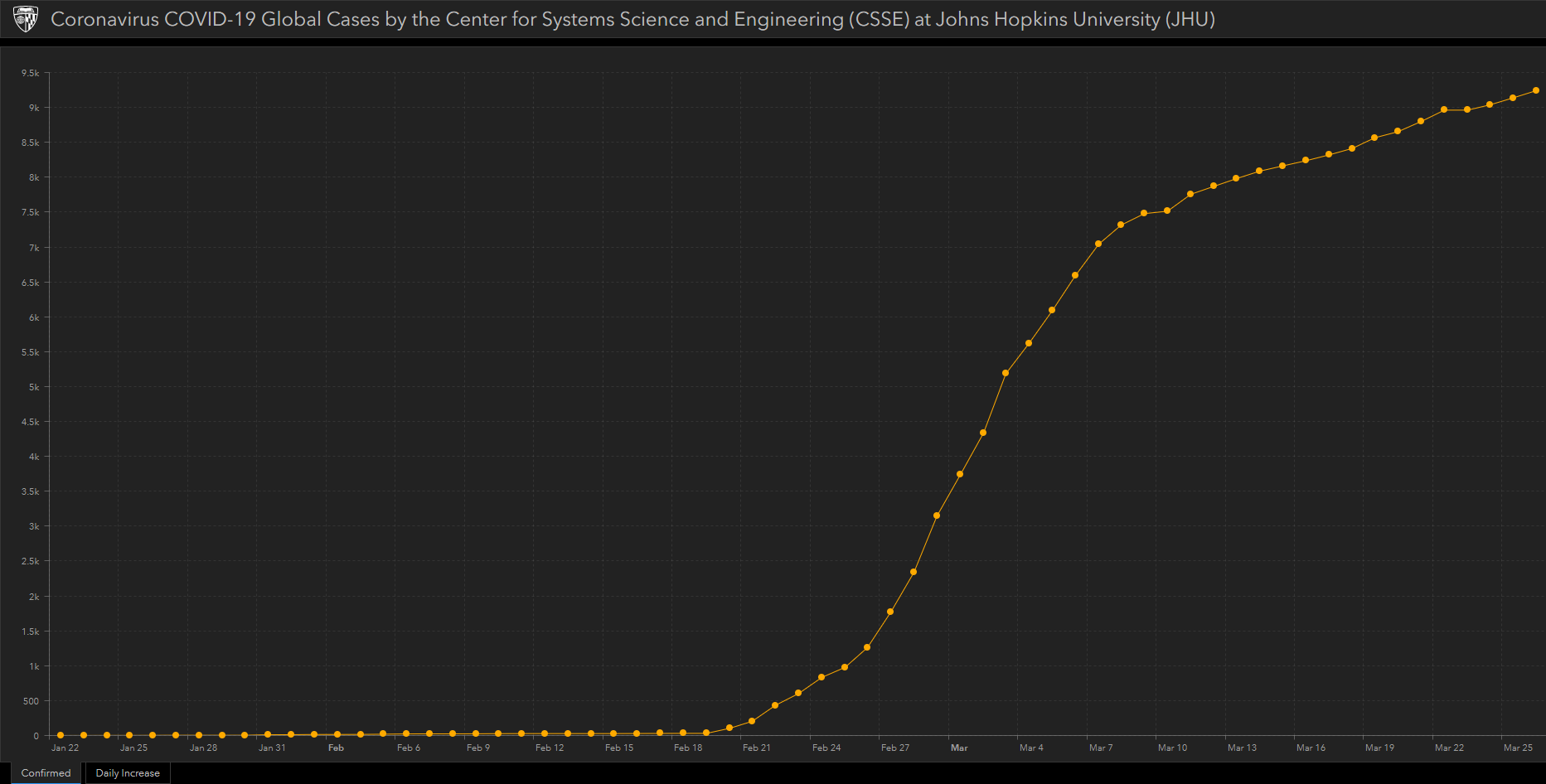
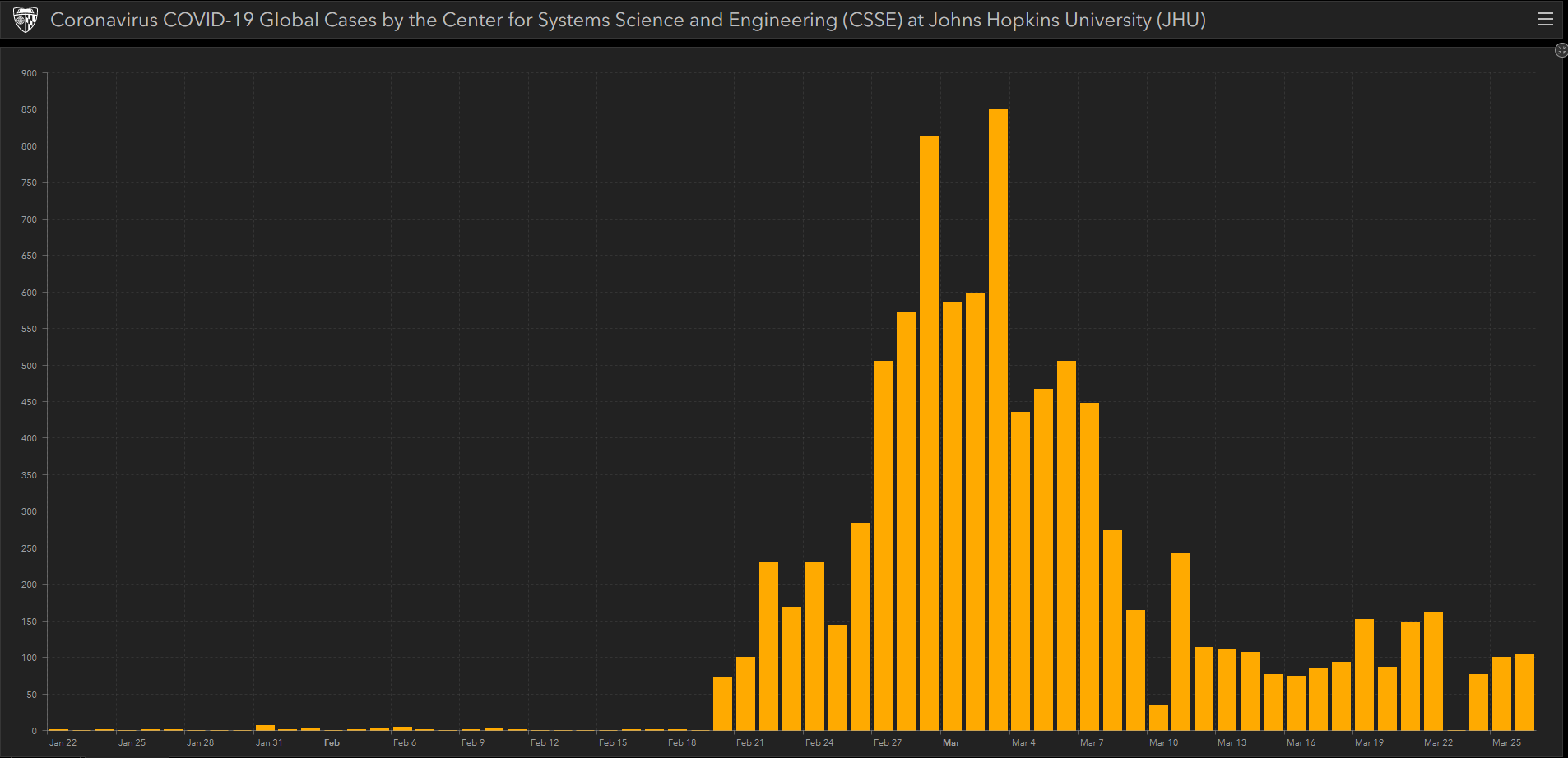


Legutóbbi hozzászólások