Nemrég sikerült teljesítenem a Data Analyst Cloudera vizsgát. De talán ne szaladjunk ennyire előre.
Készülés
 Miután egy kisdiák lelkesedésével kijegyzeteltem a training videók anyagát és memorizáltam a törzsanyagot, igyekeztem arra fókuszálni, hogy közepesen bonyolult feladatokat anélkül is simán teljesíteni tudjak, hogy a doksit vadul böngésznem kelljen. Igazából nem tartom a manual/dokumentáció böngészését eredendően elítélendő dolognak, ennek mellőzésére praktikus okaim voltak – a vizsgán használt virtuális masina erőforrásokban nem bővelkedik (bár egy tabon a Hue plusz egy terminál ablak simán ment neki), illetve elég könnyű kifutni az időből. A vizsgán csak a hivatalos Apache doksikat lehet használni, így azért érdemes valamennyi időt ezek, illetve a sqoop manual megismerésére is szánni, ne ott lássuk ezeket először, ha mégis bajba kerülnénk. Alternatív forrásként a neten találtam még felkészítő videókat.
Miután egy kisdiák lelkesedésével kijegyzeteltem a training videók anyagát és memorizáltam a törzsanyagot, igyekeztem arra fókuszálni, hogy közepesen bonyolult feladatokat anélkül is simán teljesíteni tudjak, hogy a doksit vadul böngésznem kelljen. Igazából nem tartom a manual/dokumentáció böngészését eredendően elítélendő dolognak, ennek mellőzésére praktikus okaim voltak – a vizsgán használt virtuális masina erőforrásokban nem bővelkedik (bár egy tabon a Hue plusz egy terminál ablak simán ment neki), illetve elég könnyű kifutni az időből. A vizsgán csak a hivatalos Apache doksikat lehet használni, így azért érdemes valamennyi időt ezek, illetve a sqoop manual megismerésére is szánni, ne ott lássuk ezeket először, ha mégis bajba kerülnénk. Alternatív forrásként a neten találtam még felkészítő videókat.
A vizsga teljesen gyakorlatorientált lásd oldal alján a példát, így mindenképpen ajánlott letölteni a QuickStart-Imaget (én a docker-es verziót használtam, a soványka 8 GB RAM-ommal vígan elkocogott az Ubuntumon). A VM-ben van egy retail_db adatbázis pár táblával, azokat ha sqoop-pal behúzod Hive-ba, már el is kezdheted a gyakorlást (a root/cloudera párossal pedig hozzáférhetsz a db-hez).
Ha alapos munkát végeztél, akkor tudni fogod a HiveQL és Impala közötti különbségeket, magabiztosan tudsz írni CTAS-t, tudod használni a beépített függvényeket és tudod, hogy mikor kell over-partition-by-t használnod.
Adminisztratív teendők
Az első lépés, hogy Clouderán lévő accountodhoz kicsengeted a megfelelő összeget, erre ő küld majd egy üdvözlő emailt. Egy ponton átirányított a PSI oldalára – ez egy oldal online vizsgákra specializálódva, különös ismertetőjegye az előző évszázadra jellemző webdesign. Következő lépésként kiválasztottam a vizsga időpontját, időzónámat (ő pedig udvariasan figyelmeztetett, hogy ugyan át tudom ütemezni más időpontra a vizsgát, de erre már nincs lehetőségem az utolsó 24 órában). A PSI oldalán van egy kompatibilitás-teszt, ahhoz hogy sikerüljön ez, fel kellett tegyem a PSI egyik chrome extensionjét.
Egy virtuális gép elérésénél kritikus tud lenni a késleltetés, így ha az ember fia nem bízik a csillagok megfelelő együttállásában, kezébe veheti sorsát és foglalhat meeting roomot a Cloudera Budapesti főhadiszállásán – bízva abban hogy ott optimális technikai feltételekkel tud dolgozni.
Maga a vizsga 120 perces, de előtte 15 perc adminisztratív teendőkkel telik, így a szobát ideális elfoglalni már a vizsga kezdése előtt fél órával. A vizsga során elméletileg lehet csúszás az időben, de nálam ez nem volt számottevő.
Érkezés

Amikor elérkezett az idő, felkaptam kabátom, esernyőm és belötyögtem a villamossal arra a pontra, amit a google maps megjelölt. Annak ellenére, hogy már-már védjegyem az, hogy mindenhonnan kések egy picit, meglepő módon sikerült időben odaérjek. Természetesen ez sem ment abszolút zökkenőmentesen, tekintve hogy naívan két méteres ‘Cloudera’ feliratot vártam, amit nem találtam sehol. Némi útbaigazítás után megtudtam, hogy a Roosevelt irodaház hat/hetedik emeletén van a főhadiszállásuk, így betoppantam az irodaházba. Miután ízléstelen barna műbőr kabátommal nem tudtam elvegyülni az ottani öltönyös úriemberek között, kértem vendégkártyát a Clouderához. A lift kártyával működik, így a gombok kétségbeesett nyomkodása nem segít abban, hogy az ember felkerüljön a hetedik emeletre. A recepción gyorsan készítettem vendég-matricát magamnak, amit büszkén felragasztottam kabátom mellrészére. Pár perc után odaért a kontaktom, és újabb pár perc után sikerült találniuk egy másik meeting roomot, majd lekísértek a teremhez. Összességében 5-10 perc után a szobában voltam, így megkezdhettem annak átrendezését. A redőnyöket lehúzták, táblát kivitték, én pedig elpakoltam az asztalról mindent amit tudtam, elővettem laptopom és izzadt tenyérrel vártam, hogy a PSI felületén rá tudjak kattintani a vizsga megkezdése gombra.
Vizsga
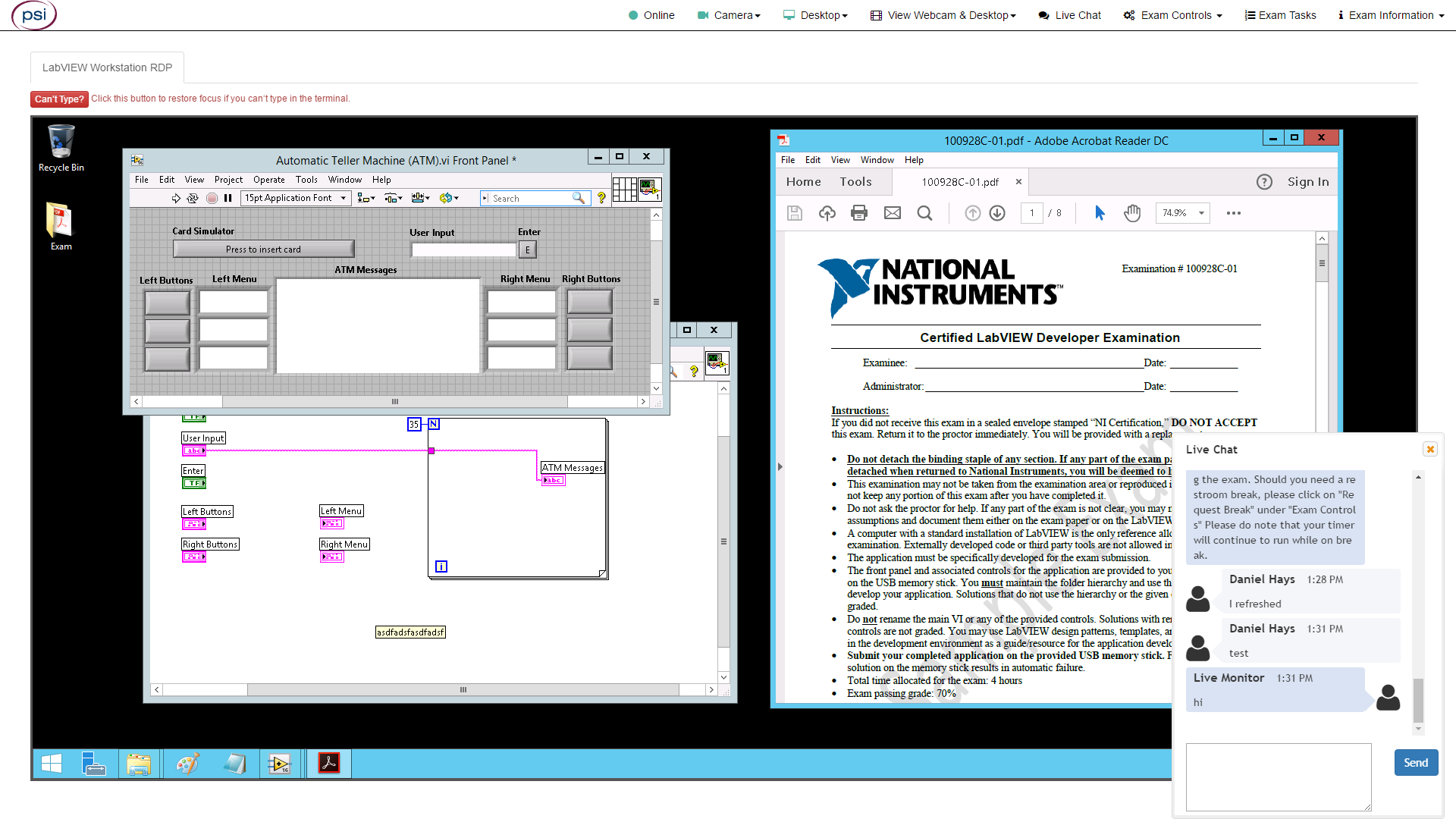
A gombra kattintás után egy felületet kaptam, egyelőre VM nélkül, ahol egy chat ablakban egy sablonszöveg fogadott, majd kértek, hogy igazoljam magam, hordozzam körbe a laptopot a szobában, mutassam meg a szoba falait alaposan, mutassam meg az asztal felületét, stb. Mivel a vizsgáról nem készíthettem képeket, így a fenti kép csak egy google képkereséssel talált illusztráció – ám arra teljesen tökéletes, hogy megmutassa a felületet. Az ablaknak háttal nem lehetett ülni, illetve a kamerában jól látszódnom kellett (utóbbi a View webcam & desktop menüpont alatt volt ellenőrizhető a felső menüsávon). A kezdés előtt a system monitort/topot kellett mutatni. Maga a vizsga kilenc rövidebb feladatot tartalmazott. Egy feladat megoldása többnyire pár percet vett csak igénybe, a neheze annak ellenőrzése volt. Gyakori kikötésként szerepelt, hogy egy másik, létező táblával megegyező formátumot kell követni (fájlformátum, tagolás, oszlopnév), így ezt reflexszerűen tudni kellett ellenőriznem. A feladatoknál nincsenek részpontszámok és automatizáltan vannak ellenőrizve, így könnyű elcsúszni az ilyen “banánhéjakon”.
Teljesítménybeli problémákat nem tapasztaltam, a lekérdezések többsége 2-3 perc alatt lefutott. Két alkalommal hiába gépeltem szöveget, kétségbeesett billentyű-csapkodásomra sem jelent meg a virtuális gépen – ez a probléma mindkét alkalommal pár perc után magától megoldódott. A touchpaddal is volt egy kevés gondom, de erről könnyen el tudom képzelni, hogy lokális probléma volt. Miután vége lett a vizsgának, kaptam egy sablonszöveget, hogy 2-3 napon belül lesznek majd eredmények. Ezeket egyébként meglepően gyorsan megkaptam – mire az immár eléggé időszerű ebédem után visszaértem az irodába, már értesítettek is arról, hogy átmentem.





Legutóbbi hozzászólások