

Itt a tél, az ünnepek után, a hosszú estéken pedig egyre többen találják meg a kikapcsolódást az olvasásban. A könyvmolyok azonban gyakran találkoznak azzal a problémával, hogy nehéz „spoilermentesen” információt szerezni egy-egy kötetről. Annál pedig kevés bosszantóbb dolog van, mint amikor egy háromszáz oldalas könyvben még a századik oldal körül is olyan dolgok történnek, amiket már olvastunk a fülszövegben. Szabó-Fischer Hanna erre keresett megoldást.
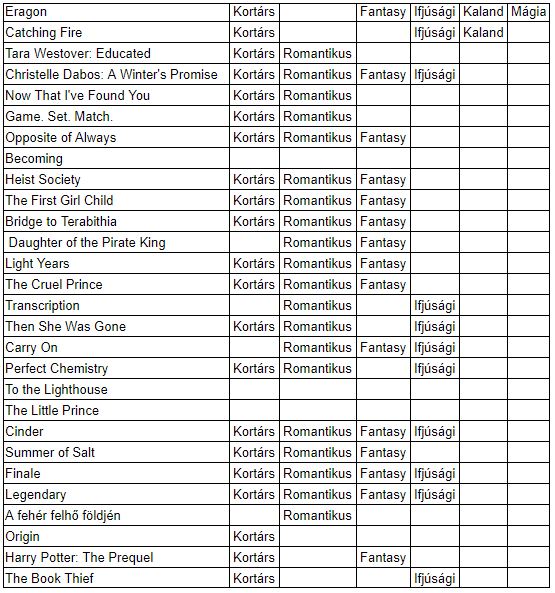
„Persze lehet találni jó fülszövegeket is, de én mára gyakorlatilag teljesen száműztem az életemből őket és igyekszem más forrásból beszerezni ezt az információt. A más forrás pedig nem más, mint a moly.hu közössége” – osztotta meg személyes tapasztalatait Szabó-Fischer Hanna adattudós, a budapesti United Consult szakértője. Mint fogalmazott, a könyvrajongók közösségi oldalán, az egyes adatlapokon a felhasználók címkéket tehetnek a könyvekre (például ifjúsági, kortárs, romantikus, fantasy, regény, novella, vers stb.). Ezek alapján viszonylag jól el lehet dönteni, hogy egy adott könyv tetszene vagy sem.
Az adattudós hangsúlyozza ugyanakkor, hogy a világirodalom olyan kiterjedt és sokszínű, hogy ez a magyar adatbázis és platform természetesen nem lehet „mindenható” a nemzetközi irodalom terén.
„Kiegészítésként a goodreads.com is a kedvenceim között van. Itt viszont sajnos nem létezik a címkézés, ami miatt elég zsákbamacska-szerűen válogatok a könyvek között. Megelégelve ezt az állapotot, arra az elhatározásra jutottam, hogy készítek magamnak egy automata címkéző rendszert” – számolt be elhatározásáról Szabó-Fischer Hanna, aki nem mindennapi projektbe kezdett a „könyvmolyproblémák” megoldására.
A projekt lépései
„Ha mi magunk olvasnánk egy fülszöveget, akkor viszonylag könnyen tudnánk besorolni kategóriákba, de ahhoz, hogy egy program értelmezni tudja, jóval több előkészületre van szükség. Először is kell egy adatbázis, amely tartalmaz sok fülszöveget és a hozzá tartozó címkéket. A program később majd ezekből a példákból fog mintázatokat megtanulni, ami alapján egy ismeretlen szöveget bekategorizál. A másik nagyon fontos lépés a fülszövegek előkészítése. A program nem egy szöveget, hanem szavak összességét fogja látni, ezért biztosítanunk kell azt, hogy a számunkra egyértelműen hasonló jelentéssel bíró szavakat (például könyv, könyvek, könyvről, könyvekről) a gép hasonlónak értelmezze” – ismertette az alapproblémákat a United Consult szakértője.

Szabó-Fischer Hanna a nyers fülszövegtől a működő programig az adatgyűjtéssel kezdve, a szövegfeldolgozáson, majd a dokumentummátrix felépítésén és az osztályozáson át – az ábrán látható folyamat segítségével – jutott el. Lássuk ezeket lépésről lépésre, kicsit a szakmai részletekbe is elmélyedve.
Adatgyűjtés
„Ahhoz, hogy osztályozót építsek szükségem volt egy viszonylag nagy tanulóhalmazra, melyet a moly.hu adatbázisát használva készítettem el. Ezer angol nyelvű könyv címét, fülszövegét és a felhasználók által rájuk aggatott címkéket töltöttem le. A scrapeléshez, azaz a tömeges adatletöltéshez a pythonban megírt BeautifulSoup nevű csomagot használtam” – ismertette a szakértő.
Szövegfeldolgozás
Szabó-Fischer Hanna tapasztalatai szerint a szövegfeldolgozás sokkal hatékonyabban működik angol szövegekre, ráadásul a Goodreads-en is többnyire angol nyelven vannak feltöltve a könyvek, így kézenfekvő volt, hogy angolra optimalizálja a programot.
A szövegfeldolgozáshoz az nltk csomag volt a segítségére, a munkát pedig a fülszövegek megtisztításával kezdte.
 Forrás: Towards Data Science
Forrás: Towards Data Science
„A tokenizálással szavakra bontottam a fülszöveget, majd minden szót kisbetűssé alakítottam, hiszen a szövegfelismerő rendszerek számára például a „Könyv” és a „könyv” sem ugyanaz. Ezután kiszűrtem a “stop szavakat”. Ezek olyan szavak, amik sokszor megjelennek a szövegekben, de önmagunkban nem hordoznak értéket. Ilyenek például a személyes névmások, létigék, segédigék vagy éppen a kötőszavak” – sorolta a lépéseket a szakértő.
Forrás: python nltk packedge

Fontos feladat volt a szavakat és mondatokat elválasztó, tagoló írásjelek értelmezése, kezelése is. A központozásnál és az egyedüli karaktereknél először a különböző szimbólumokat szűrte ki, majd a feldolgozás során egyedüli karakterként megmaradt elemek következtek.
„A lemmatization és a stemming két hasonló eljárás, összefoglaló néven szótövezésnek hívjuk. A lemmatization során minden szó leredukálódik a „gyökér szinonimájára”. A „playing” vagy a „played” például egyszerűen „play” lesz. Fontos kiemelni, hogy a lemmatization során az algoritmus figyel arra, hogy a redukált szó is szótári szó maradjon. A stemming hasonló logikával működik, azzal a különbséggel, hogy itt az algoritmus meghatározott szabályok alapján vágja vagy cseréli le a szóvégeket, így előfordulhat, hogy nem szótári szavakat kapunk eredményül” – ismertette a szövegfeldolgozás fontos mozzanatát az adattudós. Hozzátette: a számok konvertálásánál az arab számokat egyszerűen csak szöveggé kellett átalakítani.
 Forrás: Towards Data Science
Forrás: Towards Data Science
Dokumentummátrix-építés
Miután előállt a megtisztított adathalmaz, az adattudós elkészítette a szavakból az úgynevezett document-term mátrixot.
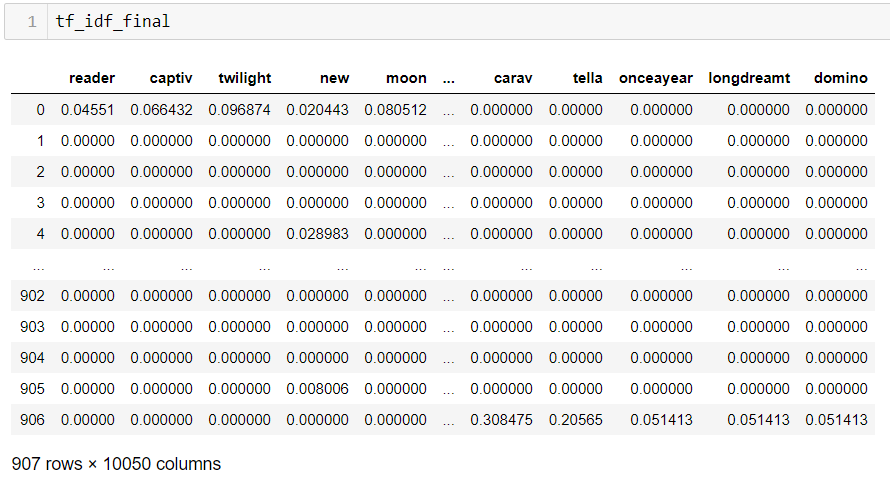
„Ez egy olyan mátrix melynek a sorai a dokumentumok – az én esetemben a fülszövegek –, az oszlopai pedig a szavak, amik előfordultak a fülszövegekben. Arra több megoldás is létezik, hogy az adott fülszövegek és szavak metszeteit miként érdemes feltölteni értékkel. A legegyszerűbb verzió, amikor 0 kerül abba az oszlopba, amely szó nem szerepelt a dokumentumban és 1-es oda, amely szerepelt. Ennél egy fokkal szofisztikáltabb módszer, amikor nem feltétlenül 1-es kerül a metszetbe, hanem a szó gyakorisága, az adott dokumentumban” – ismertette a szakértő.
Szabó-Fischer Hanna ugyanakkor nem az előbbieket, hanem egy harmadik féle módszer alkalmazott: úgynevezett tf-idf (Term Frequency — Inverse Document Frequency) mátrixot épített. Itt az egyes cellákba 0-1 közötti értékek kerültek, amelyek önmagukban reprezentálják az egyes szavak fontosságát (gyakoriságát) az adott dokumentumban és a corpusban (szókészletben) is.
Következőféleképpen számolható:
- t – term (szó)
- d – document (szavak összessége, itt: 1 db fülszöveg)
- N – corpus nagysága (az összes előforduló szó száma)
tf(t,d) = t gyakorisága d-ben / összes szó száma d-ben
df(t) = t gyakorisága az összes dokumentumban
tf-idf(t,d) = tf(t,d) * log(N/(df(t)+1))
Forrás:Towards Data Science
Osztályozás
Elkészült a dokumentummátrix, kezdődhetett az osztályozás. A United Consult senior munkatársa a tanulóhalmazból leválasztotta a címkéket, majd felmérte, hogy mekkora volumennel van dolga.
„Nagyjából nyolcszáz különböző címke gyűlt össze az ezer darab könyvhöz. Ezeket gyakoriság szerint sorba állítottam és a legnépszerűbb ötvenből kiválasztottam azt a tizenötöt, ami számomra a leginkább fontos. Minden könyvről eltároltam, hogy a tizenöt címke közül melyik igaz rá, majd a címkékre egyesével építettem osztályozókat. Ehhez az sklearn csomagot használtam. Három féle algoritmussal próbálkoztam (KNeighbors, Naive-Bayes és SVM), és ezek közül az accuracy alapján döntöttem a Naive-Bayes mellett” – avatott be a szakmai részletekbe. Az eredményekről szólva hozzátette: a legtöbb címkére 70-90% közötti pontossággal működtek az osztályozók a teszthalmazon.

Eredmények
Az adatgyűjtés után megvolt a szövegfeldolgozás, elkészült a dokumentummátrix, majd lezajlott az osztályozás is. Már csak a program hiányzott, mely a nyers fülszövegekből címkéket generál. Szabó-Fischer Hanna az alábbi ábrán látható lépések segítségével ezt is megírta:
 „Végigfuttattam a Goodreads-en lévő várólistámon, és megállapítottam, hogy tendál az egyhangúság felé. Illene szélesíteni a látókörömet” – összegezte az eredményeket az adattudós.
„Végigfuttattam a Goodreads-en lévő várólistámon, és megállapítottam, hogy tendál az egyhangúság felé. Illene szélesíteni a látókörömet” – összegezte az eredményeket az adattudós.
Néhány példa a program alkalmazására:
 „Az eredményekből látszik, hogy vannak bizonyos címkék – kortárs, romantikus, fantasy, ifjúsági –, amiket nagyon jól felismer a program, de azokra, amelyek ritkábban szerepeltek a tanuló halmazban – például humoros, női/férfi főszereplő, váltott szemszög, sci-fi, disztópia –, nem tanult rá olyan jól, és az új fülszövegekre nem alkalmazza ezeket a címkéket” – konstatálta Szabó-Fischer Hanna.
„Az eredményekből látszik, hogy vannak bizonyos címkék – kortárs, romantikus, fantasy, ifjúsági –, amiket nagyon jól felismer a program, de azokra, amelyek ritkábban szerepeltek a tanuló halmazban – például humoros, női/férfi főszereplő, váltott szemszög, sci-fi, disztópia –, nem tanult rá olyan jól, és az új fülszövegekre nem alkalmazza ezeket a címkéket” – konstatálta Szabó-Fischer Hanna.
Az okokról szólva megosztotta, hogy az alap tanulóhalmazt a moly.hu-ra angolul feltöltött könyvek jelentették, ebben a körben pedig magasan felül reprezentáltak az ifjúsági és kortárs szerzők könyvei, és talán a szórakoztató irodalom is a szépirodalommal szemben, hiszen ezt az adatbázist a felhasználók készítik, és a fiatalabb korosztályban sokkal valószínűbb, hogy valaki angolul olvas, mint az idősebbek között. Mindezek miatt a háborúkkal, gyásszal, történelmi regényekkel kapcsolatos címkék is kevésbé jelentek meg a tanuló halmazban.
„Javítani a felismert címkék sokszínűségén leginkább a tanulóhalmaz számbeli növelésével és a repertoár szélesítésével lehetne” – zárta a szakértő, aki mindezek ellenére jó szívvel ajánlja az előbbiekben ismertetett módszert arra, hogy bárki spoiler nélkül találjon az ízlésének megfelelő könyvet.
További eredmények:
 A kód
A kód
Szabó-Fischer Hanna a kódot is megosztotta, hátha valakinek kedve támad továbbgondolni az ötletet. Íme…
# SCRAPE
from bs4 import BeautifulSoup
import requests
# go through links to retrieve blurbs and tags
url = 'https://moly.hu' + link["href"]
r = requests.get(url)
# collect html
soup = BeautifulSoup(r.text, 'html.parser')
cimkek = soup.find_all('a', class_='hover_link')
fulszovegek = soup.find_all('div', class_="text")
# TEXT-MINING
def preprocessing(fulszoveg):
fulszoveg = lower_case_convert(fulszoveg)
fulszoveg = tokenizing_own(fulszoveg)
fulszoveg = stop_words_eliminator(fulszoveg)
fulszoveg = punctuation_eliminator(fulszoveg)
fulszoveg = apostrophe_eliminator(fulszoveg)
fulszoveg = single_char_eliminator(fulszoveg)
fulszoveg = converting_numbers(fulszoveg)
fulszoveg = tokenizing_own(fulszoveg)
fulszoveg = stop_words_eliminator(fulszoveg)
fulszoveg = lemming_own(fulszoveg)
fulszoveg = stemming_own(fulszoveg)
return fulszoveg
# TF-IDF
import collections
# making a dictionary which collects all the words, and collect the doc IDs for every word
DF = {}
for i in range(len(fulszovegek)):
tokens = fulszovegek[i]
for word in tokens:
try:
DF[word].add(i)
except:
DF[word] = {i}
# instead of collecting the doc IDs, we need just the counts for every word
for i in DF:
DF[i] = len(DF[i])
# all the words (keys in DF)
total_vocab = [x for x in DF]
# calcuating TF-IDF
tf_idf = {}
for i in range(len(fulszovegek)):
tokens = fulszovegek[i]
counter = collections.Counter(tokens)
words_count = len(tokens)
for token in np.unique(tokens):
tf = counter[token]/words_count
df = doc_freq(token)
idf = np.log((len(fulszovegek)+1)/(df+1))
tf_idf[doc, token] = tf*idf
doc += 1
# CLASSIFICATION
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import GridSearchCV
# train/test split
data_train=data.sample(frac=0.8,random_state=200)
data_test=data.drop(data_train.index)
# set X
X_train = data_train.drop([cimkek], axis=1)
X_test = data_test.drop([cimkek], axis=1)
# classifier for every tag
tag_list = cimkek
for tag in tag_list:
y_train = data_train[tag]
y_test = data_test[tag]
parameters = {'alpha': [0.1, 0.5, 1, 1.1, 1.2, 1.3, 1.4, 1.5, 2, 2.3, 2.6, 3, 4, 5, 6]}
naiveB = GridSearchCV(MultinomialNB(), parameters)
best_est = naiveB.best_estimator_
best_est.fit(X_train, y_train)
y_pred = best_est.predict(X_test)
print('score', best_est.score(X_test, y_test))
# PRODUCT
processed_text = preprocessing(fulszoveg)
data = instert_into_tfidf(processed_text)
result = auto_tag(data)


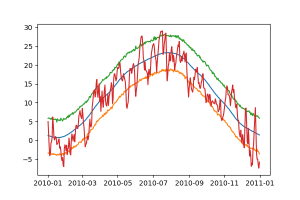 A fenti ábrán a 2010-es év valós időjárása piros vonallal látható. A Prophet által illesztett előrejelzés a kék vonal és a hozzá tartozó narancs és zöld színnel ábrázolt y_lower és y_upper, felső és alsó határérték.
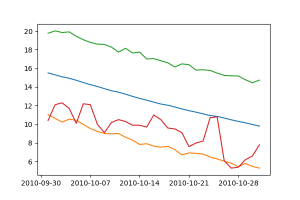
A fenti ábrán a 2010-es év valós időjárása piros vonallal látható. A Prophet által illesztett előrejelzés a kék vonal és a hozzá tartozó narancs és zöld színnel ábrázolt y_lower és y_upper, felső és alsó határérték.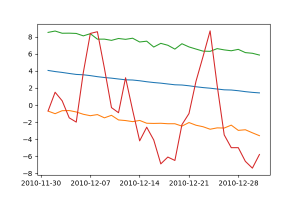

Legutóbbi hozzászólások