
A kezdeti nehézségek ellenére meglehetősen jól alkalmazkodtunk a körülményekhez és – bár a többség számára nehezen érzékeltethető – de az IT világában igenis folyik a munka. Sok esetben meglehetősen hatékonyan. Egyik véglet, amikor munka közben négy gyereket kell menedzselni egy 80 nm-es lakásban, ahol a 2 nm-es erkélyre lehet maximum kimenni, a másik véglet a szingli életmód egy belvárosi lakásban, ahol hetek óta senkivel sem találkozol. Mindkettőre könnyű példát találni. Meggyőződésem, hogy egyik sem tartható fenn huzamosabb ideig anélkül, hogy valakinek az idegállapota ne változzon jelentős mértékben. Az előrejelzések alapján azonban a jelenlegi állapot hosszú hetekig még fenn marad, hiszen ha lazítanak a szabályokon, akkor a vírus terjedése elindul. Idén tehát valószínűleg sokaknak elmarad a nyár vagy a saját lakásra/kertre, esetleg nyaralóra, de mindenképpen a szűk családi körre koncentrálódik.
Hatékony járványkezelés, lehetséges?
A híreket olvasva kerestem példákat, hogy más országokban mi a helyzet. Azt már tudjuk, hogy hogyan ne kezeljük a helyzetet, látva az olaszországi, spanyol és francia példákat, ahol százak halnak meg naponta a vírustól. Vajon azt tudjuk hogyan lehetne másképp, jobban kezelni, hogy a vírus ne terjedjen, ugyanakkor a korlátozások se legyenek ilyen drasztikusak? Van erre példa, méghozzá Dél-Korea.
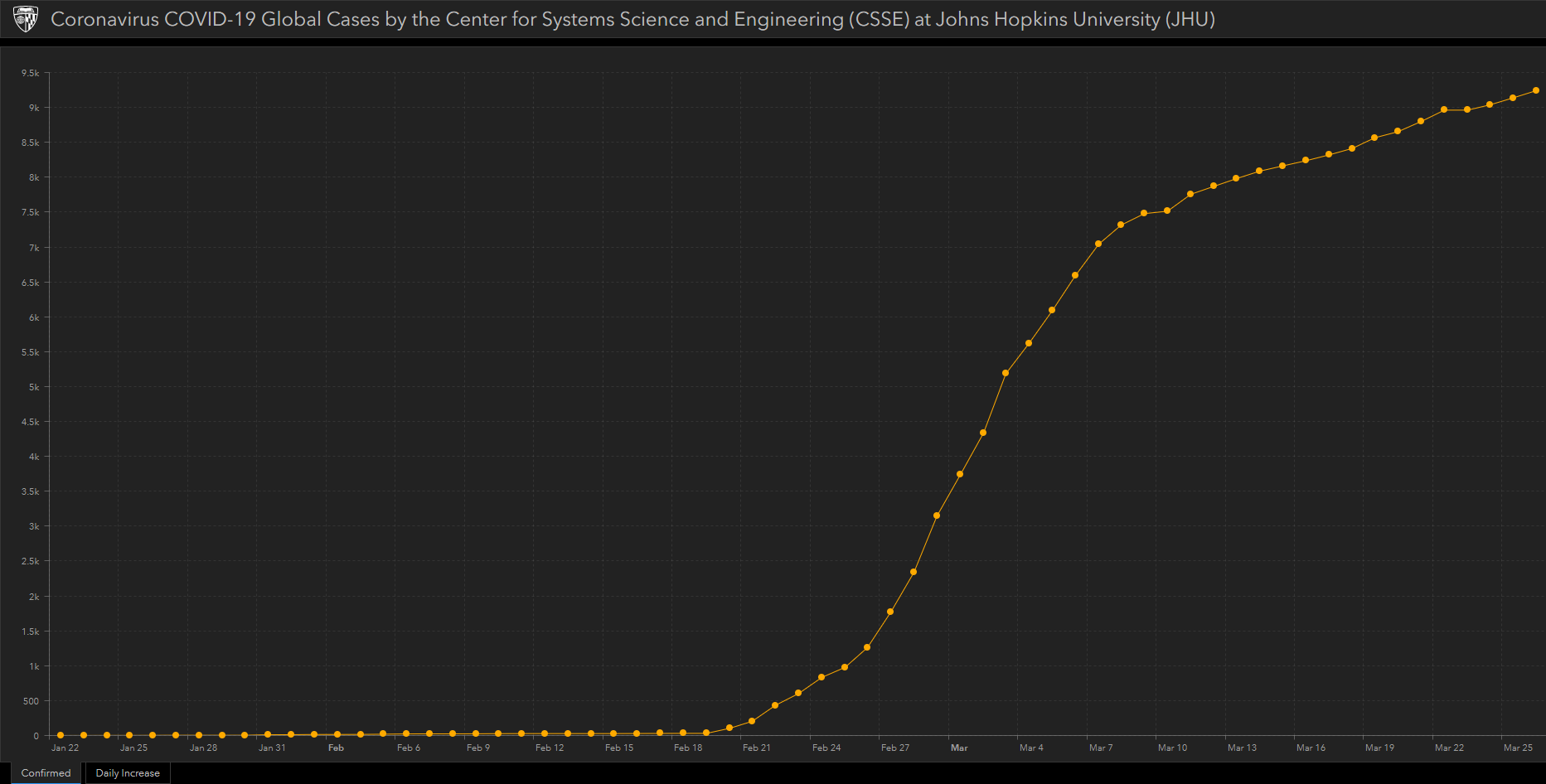
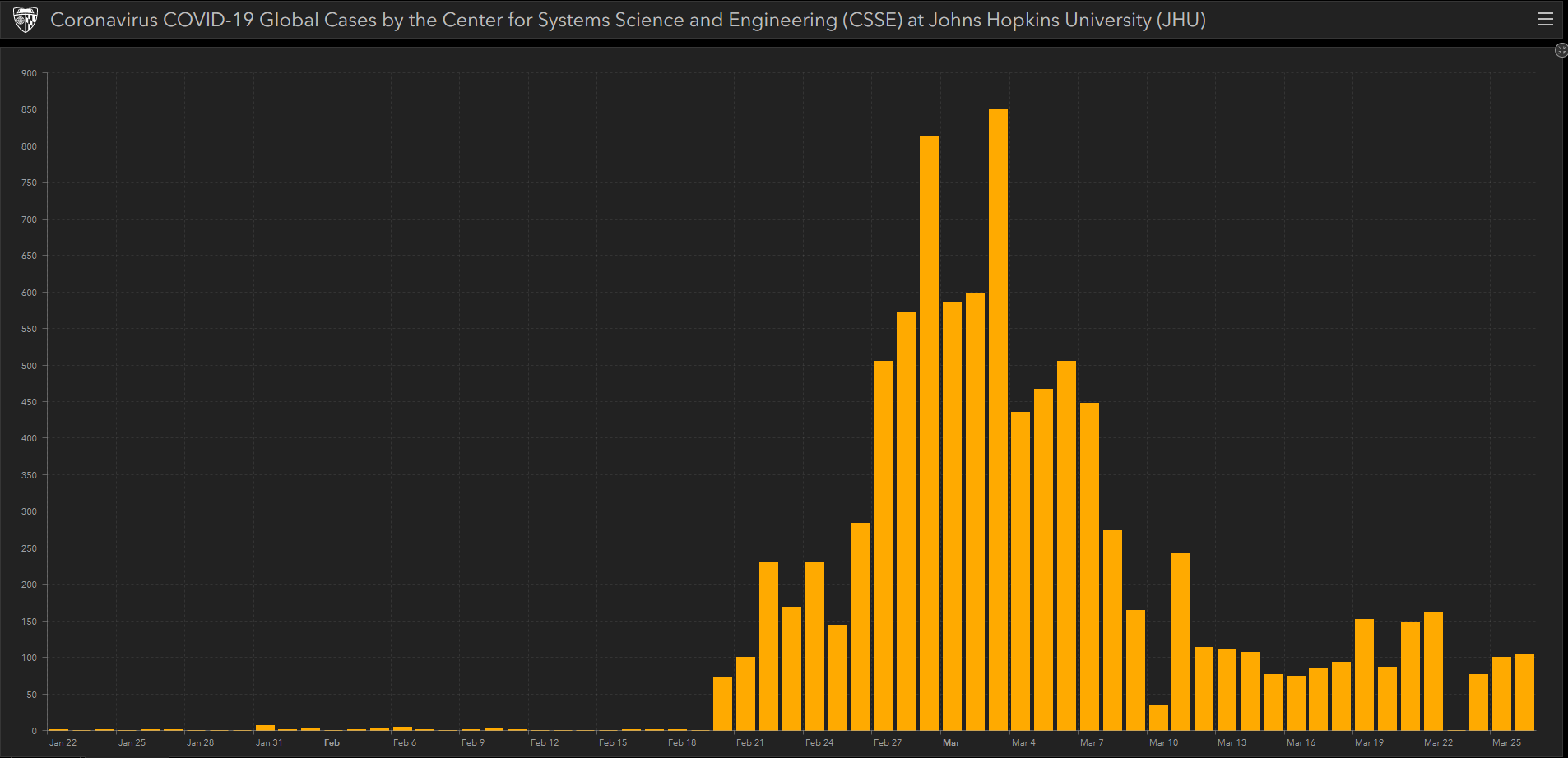
Dél-Koreában ugyan több, mint 9200 fertőzést regisztáltak (2020. március 26-i adat), a lakossághoz és a népsűrűséghez mérten ez egyáltalán nem sok. A megdöbbentő azonban, hogy milyen gyorsan úrrá lettek a vírus terjedésén: február 20-án regisztálták hivatalosan az első fertőzötteket és március 4-én már meg tudták törni a lendületet, majd 8-án újra egy törés, március 12-e óta pedig átlagban, kevesebb, mint 100 új esetet regisztrálnak naponta.
A Wikipédia szerint Dél-Korea lakossága körülbelül 51 millió fő, 1960 óta megduplázódott. (Érdekesség, hogy eközben, a hasonló népességű Irán lakossága majdnem megháromszorozódott.) Földrajzilag szomszédos Kínával (ahonnan a vírus elindult), de közvetlen szárazföldi kapcsolata Kínával nincs. Szárazföldi kapcsolata Észak-Koreán keresztül van, Észak-Korea zártsága miatt arra viszonylat kevesen járnak. Így a határai jól kontrollálhatóak, vízi és légi kikötőkre korlátozódnak. Azonban nem ennek a sajátos helyzetnek köszönhetik, hogy ilyen jól kordában tudták tartani a vírus terjedését. A háborút még ők sem nyerték meg, de sok csatát már megnyertek és jók a kilátásaik a végső győzelemre.
A Max Fisher NYT újságírójának beszámolója alapján Dél Korea a felkészültségének és a hihetetlen professzionizmussal végrehajtott „hadműveletének” köszönheti a hatékony védekezését. A „hadművelet” négy fontos részből áll:
- Gyors beavatkozás, még a krízishelyzet kialakulása előtt (Lee Sangwon, an infectious diseases expert at the Korea Centers for Disease Control and Prevention said: “We acted like an army,”)
- Korai tesztelés, gyakran és biztonságosan (hogy nehogy az orvos/nővér is megbetegedjen)
- Kapcsolatok követése, izolálása és megfigyelése
- Lakosság segítségül hívása, bevonása
Ezen pontok egyike sem egyszerű önmagában, de mind a négy pont hatékony végrehajtása és összehangolása nagyon komoly felkészültséget feltételez. Dél Koreában valószínűleg tanultak a 2002-2004-es első SARS hullámból. Sajnos vagy szerencsére abból Magyarország, de még a teljes Európa is majdnem kimaradt, az EU-ban mindössze Franciaországban volt halálos áldozata és a legtöbb országban hivatalosan nem is jelent meg a fertőzés. Dél-Koreában viszont igen, igaz csak 3 igazolt esetben.
Ennél is talán fontosabb a 2012-ben kirobbant Közel-keleti légúti szindróma (MERS) járvány, ami Dél Koreát 2015-ben érte el és “küldött” közel 6800 főt karanténba.
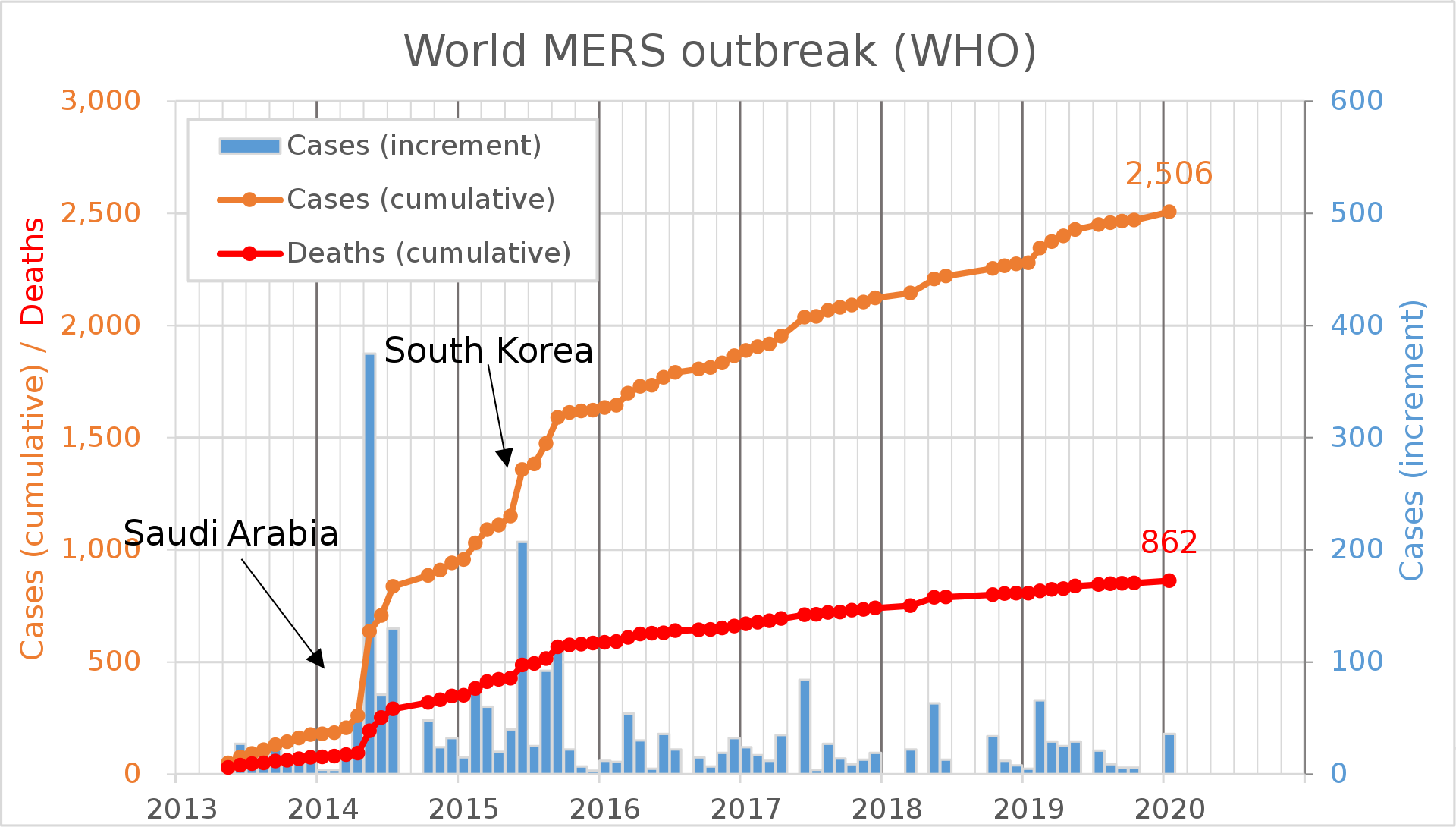
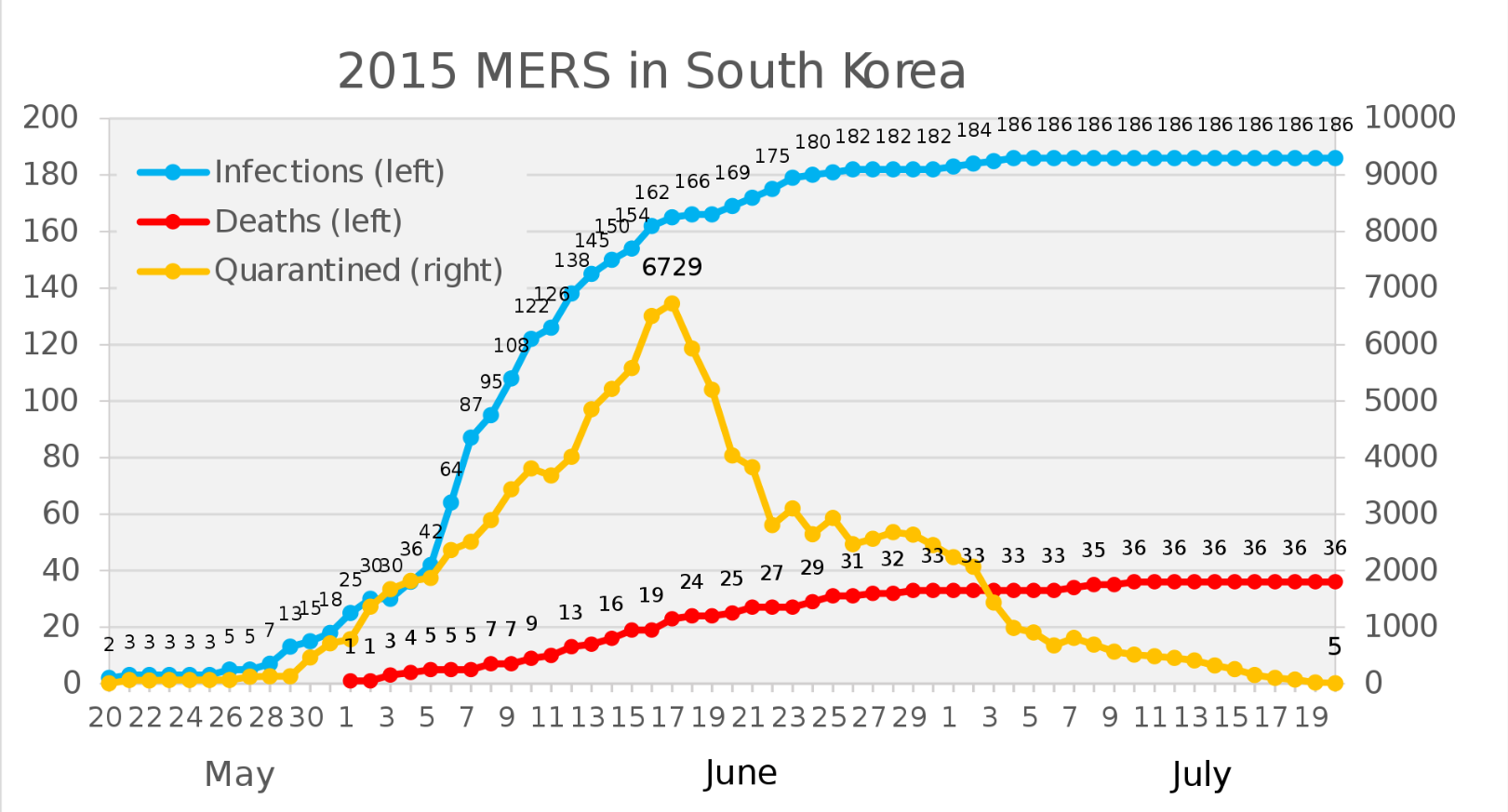
Forrás: https://en.wikipedia.org/wiki/2002%E2%80%932004_SARS_outbreak
Feltehetőleg ez készítette fel a koreai hatóságokat, hogy hogyan kell védekezni egy világjárvány ellen, hogyan védjék meg a lakosságot, főként azt a ~13,6%-ot (~7 millió embert), aki 65 éven feletti.
Az első két pont (gyors beavatkozás, gyors döntéshozatal, jó stratégia megalkotása és a korai tesztelés) abszolút a felkészültségről szól. (Van-e például a raktárban tömegesen olyan teszt, ami kimutatja a vírust?) A negyedik pont számomra evidens egy hatékonyan működő társadalomban a tájékoztatás, a kommunikáció nagyon fontos, hiszen bármit kitalálhatsz, ha az embereket nem tudod magad mellé állítani, akármilyen jó is az ötlet, nem fog működni.
Technológia jelentősége a járványkezelésben
A harmadik pont az ami engem érdekel, technológiai szempontból ez a legérdekesebb. Hogyan tudunk egy 51 millió fős lakosságot hatékonyan lekövetni, izolálni és megfigyelni?
A válasz nem is olyan bonyolult az adatok világában. Egyrészt nem 51 millió embert kell egyszerre megfigyelni, csak azt, aki közvetlen kapcsolatba kerül olyan emberrel, aki fertőzött. Miután a tömeges teszteléssel hatékonyan beazonosították egy adott területen, hogy ki a fertőzött és ki nem, már csak azokra kellett koncentrálniuk, aki fertőzött. A mobiltelefonok világában technológiailag nem túl bonyolult lekövetni, hogy ki merre jár. A Google Maps Timeline–on például most is meg tudom nézni, hogy két éve március 15-én éppen merre jártam. Sőt még azt is, hogy mivel közlekedtem: gépkocsi, kerékpár vagy gyalog. Persze ez nem mindenkinél engedélyezett és egy más kérdés az, hogy kivel osztom meg, de a mozgás követése évekre visszamenőleg adott, hiszen egy globális helymeghatározó eszközt hordanak az emberek a zsebükben, aminek neve: okostelefon. Mindegy, hogy Android vagy iOS, legfeljebb az a különbség, hogy melyik gyártó szerverére küldi az adatokat, ha nincs ez a funkció letiltva.
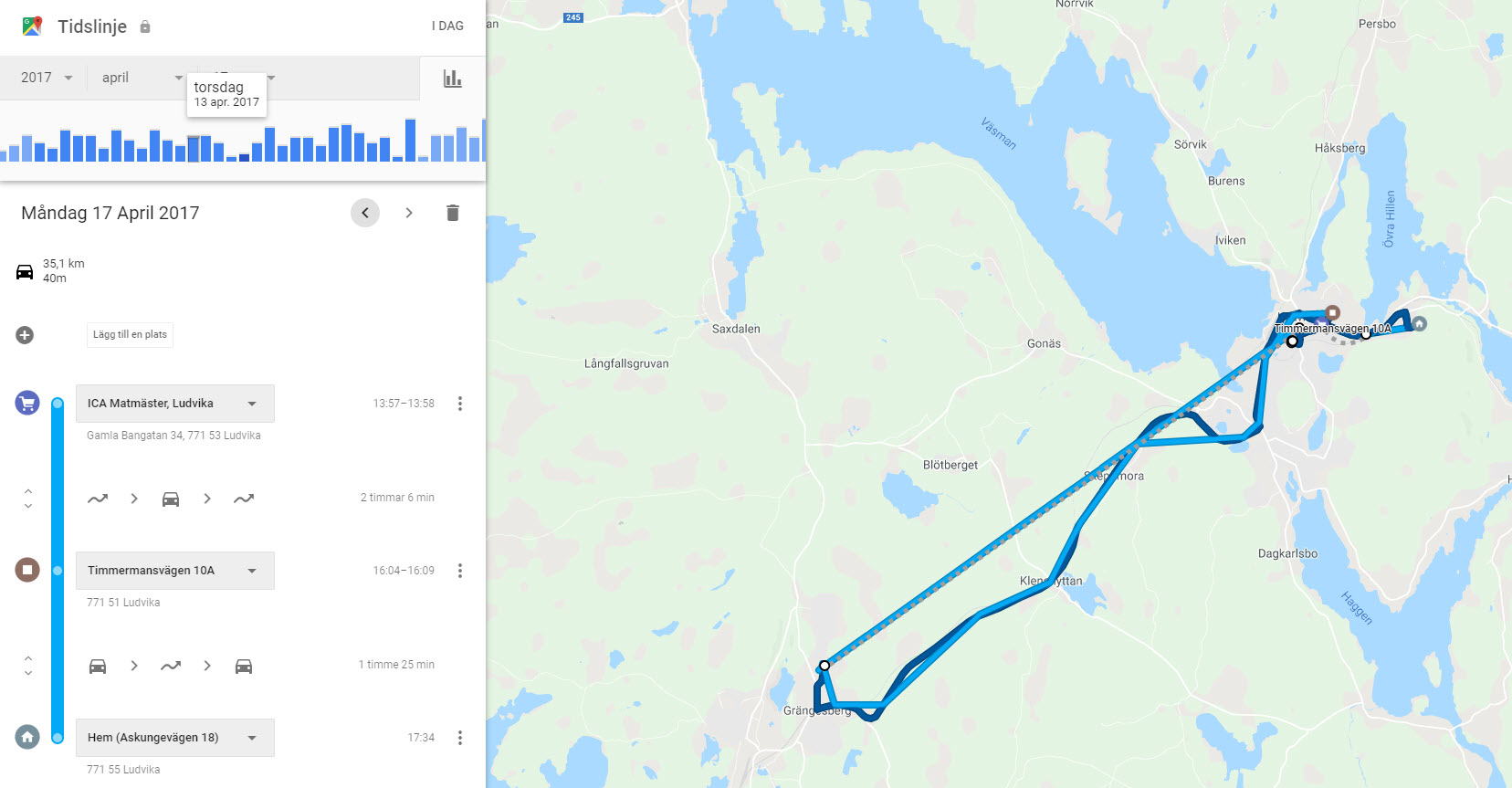
Magyarországi helyzetkép
Jelenleg 5,3 millió (~57,4%) okostelefon használó van Magyarországon, úgyhogy ezzel még nem oldottuk meg fertőzöttek követését, csak nagyjából minden másodikét, feltételezve, hogy megkapjuk az engedélyt az adatok beszerzésére.
A GPS koordináták követésén kívül van azonban egy nem közismert, de más kontextusban gyakran használt megoldás. Bárkinek a mozgása, aki mobiltelefont használ a mobilhálózaton keresztül, ha nem is GPS pontossággal, de lekövethető. Az adatok magyarországi használata nem is példa nélküli, a Nemzeti Turisztikai Ügynökség például vásárolt és elemzett ilyen adatokat nem is olyan régen.
A pontosság a hálózat sűrűségétől és a beállításaitól persze nagy mértékben függ, de a célnak megfelelő és azt a tévhitet is el kell vetni, hogy csak azok a mobiltelefonok követhetőek le, amelyek éppen hívásban vannak. Minden bekapcsolt állapotú mobiltelefon lekövethető. Erre egyébként a hazai mobilszolgáltatók céges gépjárműflotta követésére már több, mint 10 éve nyújtanak szolgáltatást (Mobil Flotta, Flotta Helymeghatározó vagy Flottakövetés).
Itt jön képbe a Big Data
Tegyük fel, hogy az adatok elérhetőek. Innentől egyszerűen csak össze kell vetnünk a koordinátákat időben és térben és le kell fejlesztenünk az algoritmust, ami akár valós időben megmondja, hogy egy kiválasztott időpontban ki találkozhatott az útja során fertőzött személlyel. Ha ezt a megfigyelt körnél automatikusan végezzük az elmúlt két hétre, akkor az eredmény a másodperc töredéke alatt lekérdezhető. Igen, akár Magyarországon is!
Az adatok hatékonyt tárolását számos Big Data megoldás támogatja, és kapacitáshiányban sem szenvedünk a felhőmegoldásoknak (például AWS, Azure, GCP) köszönhetően, de ha például ez nemzetbiztonsági kockázatot jelent, akkor építhetünk magunknak Hadoop rendszert, például egy on-prem Cloudera clustert, amit “olcsó” hardveren üzemeltethetünk és tárolhatunk benne akár petabyte (10^15 byte) méretű adathalmazt is, amelyet másodpercek alatt fel lehet dolgozni.
Megtalálni a megfigyelt személy útját keresztező személyeket nem triviális. Számos oldalról meg lehet közelíteni és kis kutatással, kész algoritmust is találhatunk az Interneten, például itt. Az algoritmus (akármilyen hatékony is) feldolgozó-kapacitást igényel, de ez 2020-ban szintén nem lehet akadály. Megfelelően méretezett on-prem clusteren vagy a felhőben elérhető a megfelelő “processing capacity”. Sőt manapság már a tárolás és a feldolgozás nem feltétlenül kell egy helyen legyen, “csak” a két hely között mozgatott adatmennyiségre kell figyelni, hogy a hatékonyság ne vesszen el. Költséghatékonyan megoldani persze semmit sem egyszerű, de nem is lehetetlen. Minden technológia és tudás is adott hozzá a csapatunkban.
Az algoritmus eredménye birtokában, akár a fertőzési valószínűséget számító Machine Learning modellekkel, SMS formájában értesíthető minden potenciálisan érintett személy és ezáltal elirányítható egy tesztközpontba.
Személyiségi jogok
A járványkezelés kapcsán sokszor felmerül a személyiségi jog kérdésköre, úgy ahogyan bármilyen üzleti célú adatgyűjtés, BigData és Machine Learning alkalmazása kapcsán is.
Véleményem szerint a járványkezeléssel kapcsolatban, ahol a hatékonyság elmaradása emberéleteket követelhet – szemben mondjuk egy üzleti alkamazással, ahol “egyedül” a profit áll szemben a jogokkal – a társadalmi igény magasabb szintet kell, hogy képviseljen, mint az egyén személyiségi joga.
Ettől a morális vitától függetlenül, a vázolt technológiai megoldás, a cellainformációkon alapuló kontakt kutatás anonimizált módon tudna zajlani. A szolgáltatók az adatvagyonnal jelenleg is rendelkeznek és úgy vélem, hogy az adatok anonimizált “átadása” egy központi járványkezelő szerv számára semmilyen törvényi akadályt nem sértene, de ennek a kérdésnek a megválaszolása természetesen már a szakjogászok feladata.
Hogyan tovább?
A koronavírus kapcsán talán már késő egy ilyen megoldás megvalósítása, de addig érdemes a témát napirenden tartani, amíg forró, hiszen egy esetleges következő járvány során a megvalósításba fektetett költségek elenyészőek ahhoz képest, hogy akár a társadalom az emberéleteken keresztül, akár a gazdaság a szigorú és hosszan tartó korlátozások hatására mekkora károkat szenvedhet el.
A dél-koreai példából is jól látható, hogy ha erre valaki fel van készülve és tömegesen, hatékonyan tudja végrehajtani a védekező intézkedéseket, akkor a járvány komolyabb korlátozások nélkül, meglehetősen rövid idő alatt kordában tartható.
Azt hiszem egyik ország sem kezelheti másként a helyzetet, legfeljebb ellaposíthatja a szigorú intézkedésekkel a vírus terjedésést, és elodázhatja ezeket a feladatokat. Hosszú távon – véleményem szerint – ez a rendkívüli állapot nem fenntartható anélkül, hogy komolyabb – nem feltétlenül közvetlenül a vírus okozta – károkat szenvedjünk. Így vagy úgy, mindenesetre jobb ha megtanulunk mindezzel együtt élni.


Legutóbbi hozzászólások